
Audit logs are all sort of records that corresponds to any changes within the application. Most importantly, while designing an audit log service we should understand which fields to audit when an event occurs. The information included in the log should provide the context of the event - the ‘who’, ‘what’, ‘where’, ‘when’ and anything else of relevance.
Audit log should be capable of storing complete track records of your system’s operations. These audit logs can give an administrator invaluable insight into what behavior is normal and what isn’t. Also, this can be useful in identifying whether a system component is misconfigured or likely to fail.
There are many reasons why we need an audit log and a few are listed below.
For better security
For faster troubleshooting
For compliance issues
For IPO readiness
For better business insights
Let’s dive deep into the various approaches for audit log service each having its own set of pros and cons.

Create a separate service that will create audit logs whenever any update occurs.
This service will be plugged into all core services wherever updates are happening.
It must be in the same transaction boundary. This means failing to update a user should roll back the audit logs.
The database schema looks something like this:
KEY_TYPE: users, SUB_KEY_TYPE: name (column or a logical collection of columns), KEY_ID: users.id, FROM_DATA: original data in serialized form, TO_DATA: changed data in serialized form.
Allows adding custom metadata.
The developers have the full freedom to design their own way.
Tight coupling. Lots of overhead involves in maintaining the code.
Transactional issues might be frequent if not handled carefully.
Writing audit logs will increase the number of executed statements for each update, hence increasing the response time of the application.
Changes done directly from database cannot be tracked.
The design diagram looks like the following.
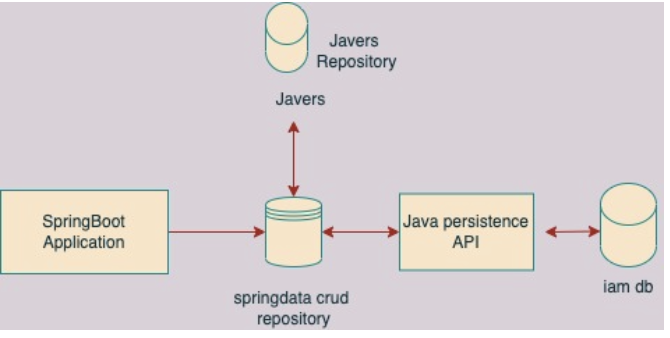
Annotation-based over repository class.
It doesn’t create new connections to the database, reuses the same connections.
Audit data is committed or rolled back along with application data in the same transaction.
Adding JaVers dependency into your Spring Boot Application will automatically create a table schema as defined below:
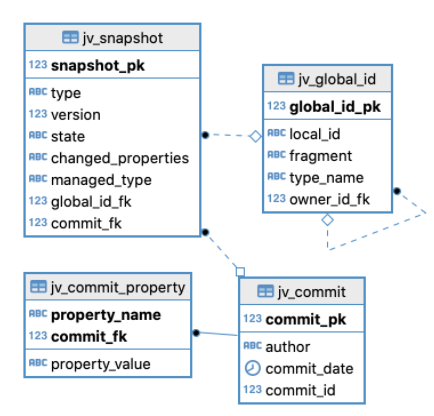
| jv_snapshot | Contains logs data |
| jv_global | Contains entity information for the data which is changed |
| jv_commit | Who performed the updates |
| jv_global_id | type_name: Stores the table name / object |
| jv_snapshot | changed_properties: Contains the column_name that is changed state: Stores the current state of a table object |
Performs best when the system is read-heavy.
Can easily be integrated with the Spring Boot application.
Requires almost zero configuration changes.
Custom metadata can be added.
Easy query to get snapshots change of selected entities.
Writing audit logs increases the number of executed statements for each update, hence increasing the response time of the application.
Changes done directly from the database cannot be tracked.
The design flow diagram looks like the following.
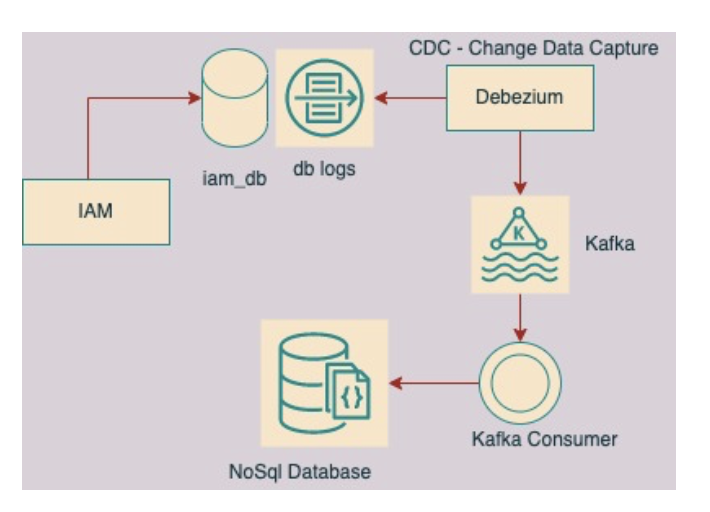

There are quite a few variants of CDC available in the market such as RedHat’s Debezium, Netflix’s DB Log, and LinkedIn’s Brooklyn.
Debezium can write data only in Kafka — the primary producer it supports. On the other hand, MD supports a variety of producers including Kafka.
Any update occurring on the database creates a transaction log regardless of whether it is created from a DB query or an application. Thus, data change events can be produced.
Best standard practices to capture audit logs when the system is write-intensive.
Requires time to explore.
Separate stacks need to be maintained for Debezium, Kafka, etc.
Joining and combining logs could be challenging.
Requires Kafka Stream as an overhead.
The design flow looks like the following.
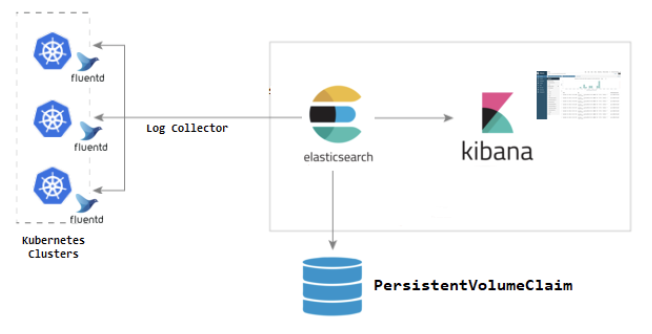
EFK is a suite of tools combining Elasticsearch, Fluentd, and Kibana to manage logs.
Fluentd collects the logs and send them to Elasticsearch. Elasticsearch receive the logs and save them on its database. Kibana then fetches the logs from Elasticsearch and displays it on a web app.
This could be easily installed on Kubernetes.
This is the best practice for dealing with application logs.
Capturing DB change logs could be challenging.
While designing the Audit Log Service, we evaluated the above-mentioned options and choose the JaVers Spring Boot approach. The selection of the right approach largely depends on the nature of the application. Our application is a Spring-based Microservice experiencing medium traffic and we needed to develop it as fast as we could.
Before designing the Audit Log, it is very important to get the requirements from the ground team and know the existing problem that they are facing in absence of an audit feature. This will help identify the extra metadata information like IP address, browser information, user meta information, etc. Such metadata needs to be captured and stored along with the regular audit logs.


Sign up with your email address to receive news and updates from InMobi Technology