

Traditionally, data platforms have always followed a centralized approach, where all the responsibilities concerning storage, availability, quality, governance, discoverability etc. are owned by a single division within an organization. This segregation between data producers (applications) and data providers (data platforms) have enabled platforms to evolve independently. However, it has also led to the creation of a singular dependency that needs to support all the data requirements by having deeper context on data being pushed across multiple domains, while abstracting away data producers from their real-world consumers.
This could be overcome by moving data availability in directly consumable format closer to the data producers. This will lead to a decentralized setup where data producers are responsible for exposing data over an interface very similar to a platform API, with the central data platform to act as a data aggregation and orchestration gateway, which is similar to an API Gateway.
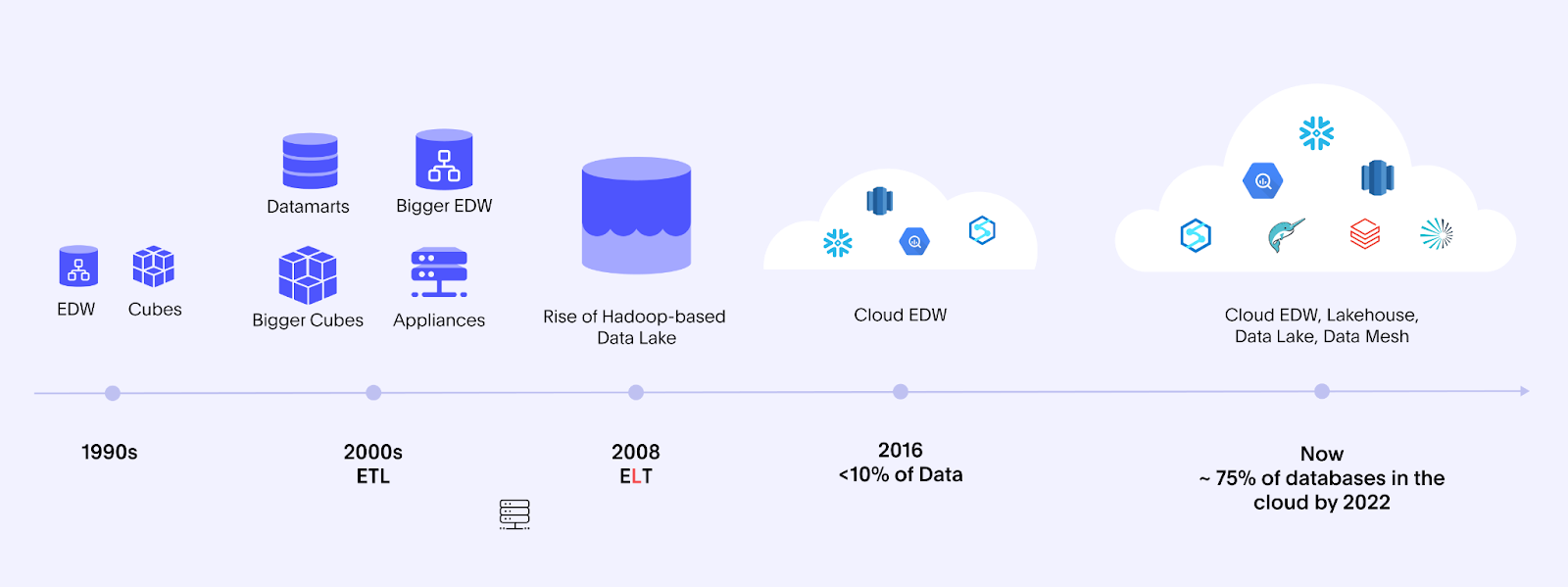
These were the times when we had just the databases and logs with basic data warehouses mirroring operational data when commands like tail and grep were used.
Analytics on top of operational data.
Could not support rapidly growing structured and unstructured data.
High cost to scale.
This is the classical model of addressing data at central destination. The application services (producers) would emit datasets to different outputs like databases, logs, events, etc. The unstructured and partially structured datasets needed to be imported into a landing zone. Then a series of ETL jobs owned by the central teams performs the cleanup activity – making it available in a staging area for consumers like BI, AI/ML and even other services that need operational data.
Low-cost storage to hold raw and unstructured data – HDFS, AWS S3
Open data formats on top of distributed file system: ORC Parquet
ETL Jobs: MapReduce, AWS EMR
Growing pile of unstructured data.
Series of ETL jobs required to cleanup and collate data that essentially separates garbage from useful records.
Delay in final availability of data can range from hours to days.
Duplicate records.
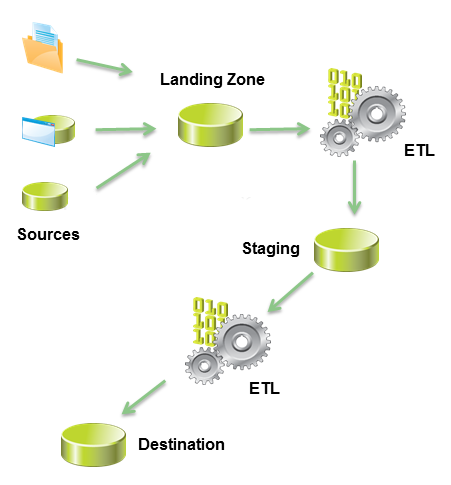
Unstructured data cleanup using ETL
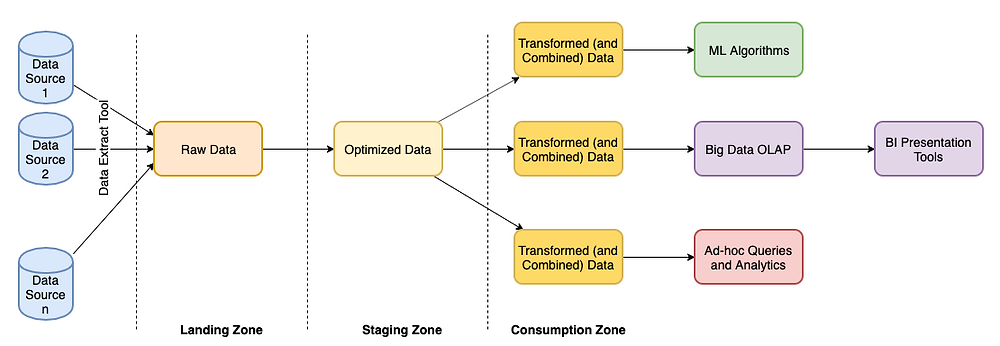
Raw data from producers pushed/pulled into landing zone and optimized further
This was the first phase of tech stack evolution. Reporting and BI tooling stack transformed from Reporting Databases like Oracle DWH to adding Analytics support through Data Lakes like Hadoop and MapReduce. Further to a unified setup where features like structured records with optimal format (Parquet), partitioning and high-performance querying (Spark) were introduced to enable DWH and Date Lake features on single stack. Hence the term Lakehousefd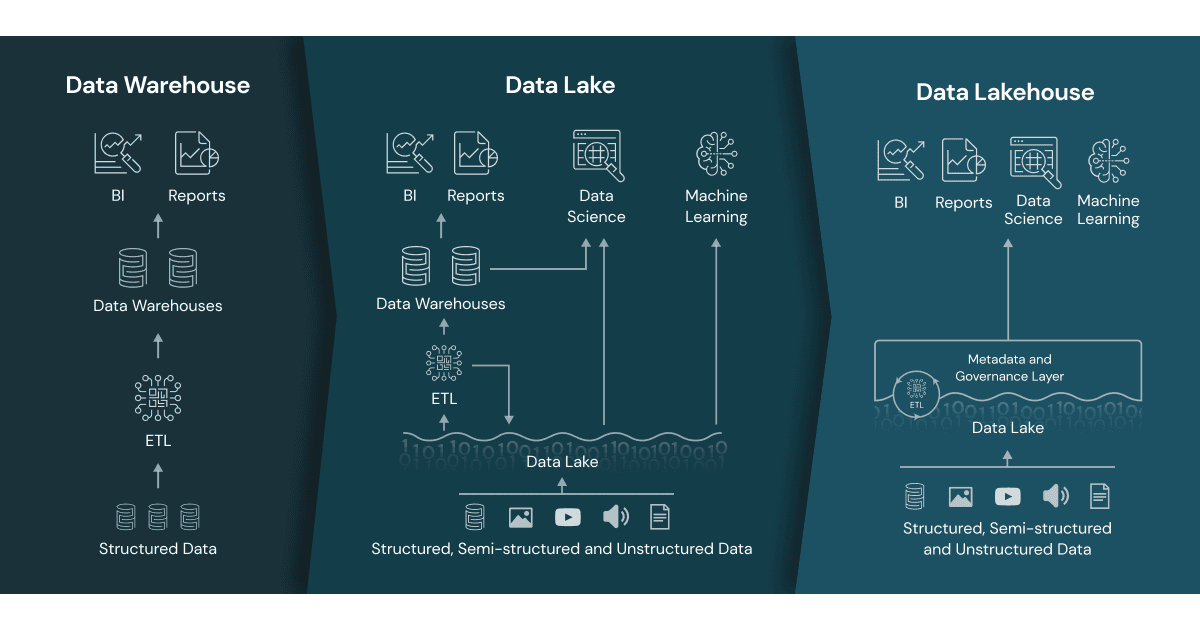
Date Lake + Data Warehouse → Data Lakehouse
This model shifts the responsibility of providing the data in proper format to the data producers. This is typically done by the producers by emitting properly structure data or using in-flight processors like log formatters (Grok in Logstash) or event processors (Spark or Flink). However, the event/data structure definition is defined and governed by a central platform that is still responsible for creating and owning the right schema metadata for its consumers.
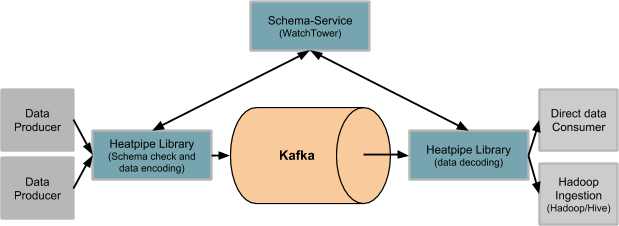
Data producers publishing data with central schema validation
This was the second phase of tech stack evolution. Traditional Data Lake/Warehouse design works on the concept of pulling data into the Lake/Warehouse and use that for reporting, analytics etc. (remember Sqoop imports!). Data Fabric builds on the concept of directly querying the source of truth, which requires an orchestration and aggregation layer that can work across different data stacks like Hive, RDBMS, NoSQL, Snowflake, Blob, Databricks etc. and different locations (multi-cloud), like Presto, Amazon QuickSight, Apache Impala, etc.
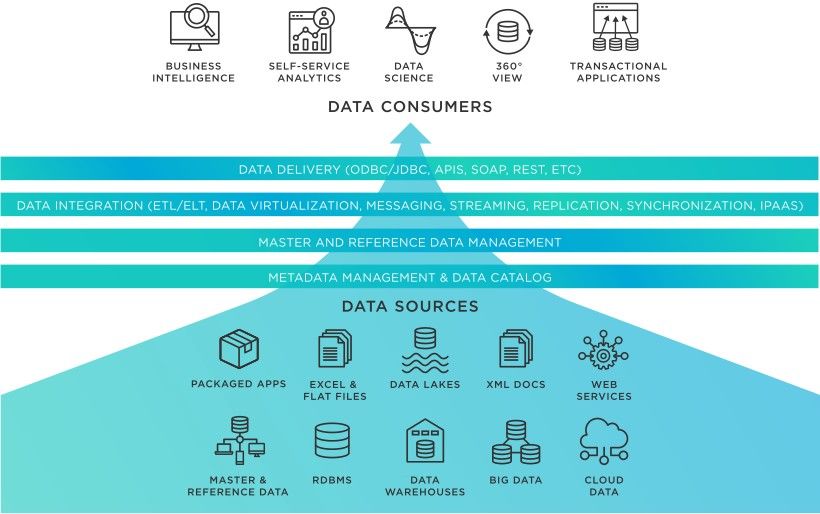
Data Fabric – The data federation stack
Data mesh co-locates the data next to data producers, where the data in a consumable format is stored and made available by the respective application group, and its responsibility is to maintain the quality, availability, storage, and governance of the data. The role of the platform is to provide a common indexing or discoverability layer where all the data sources are on-boarded in for easy discovery.
Can the central discoverability layer also be decentralized using blockchain?
Domain oriented decentralized ownership
Localize storage close to source
Federated query/computational governance (data sources equivalent of GraphQL)
Global standard which facilitates interoperability (equivalent to REST standard for API)
Data as a product is provided by the data producers
Self-serve data infrastructure as a platform for both producers and consumers
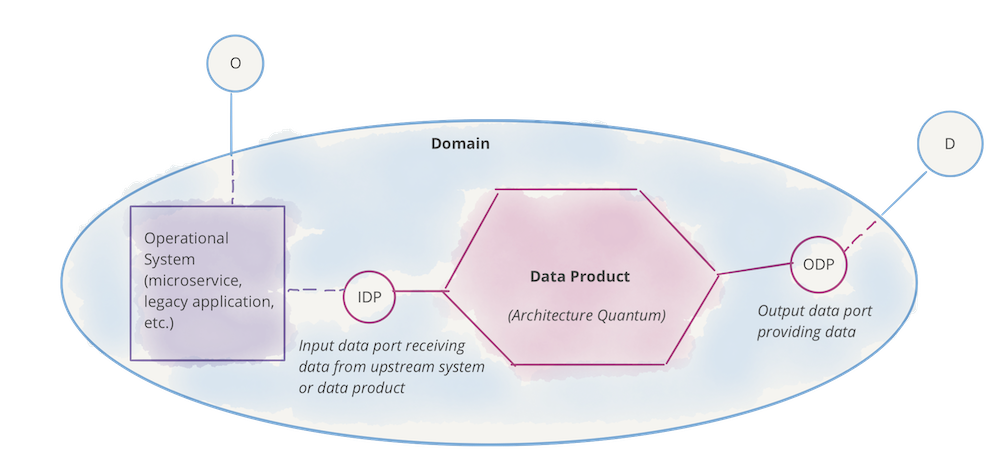
Individual domain data providers
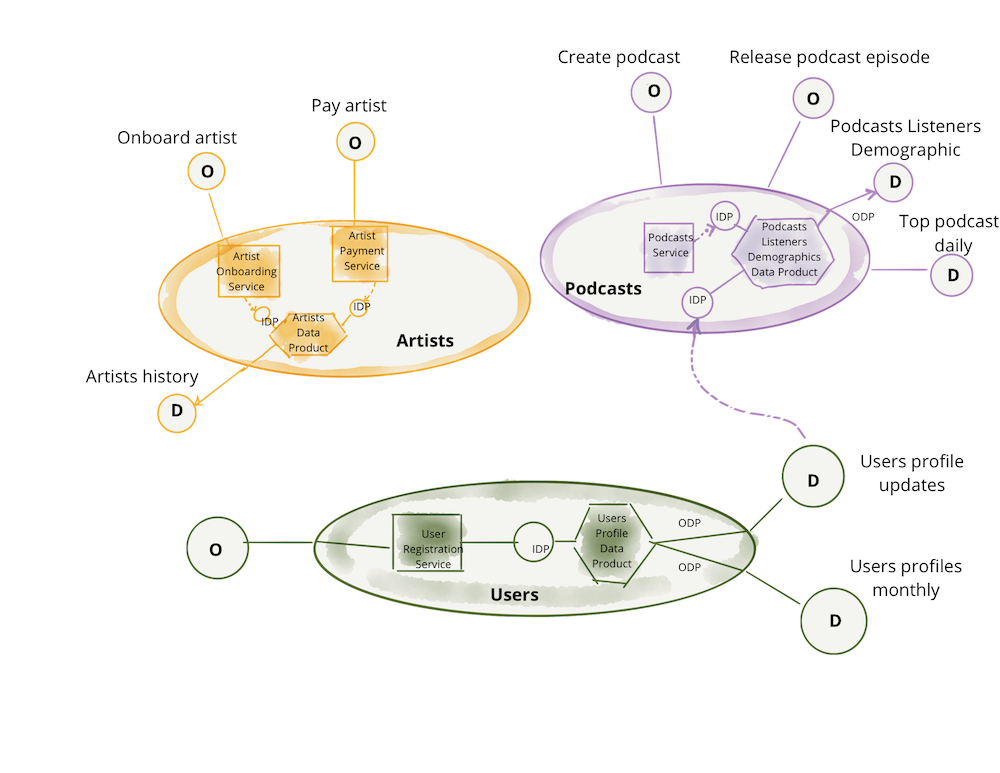
Domain services providing and consuming data similar to APIs
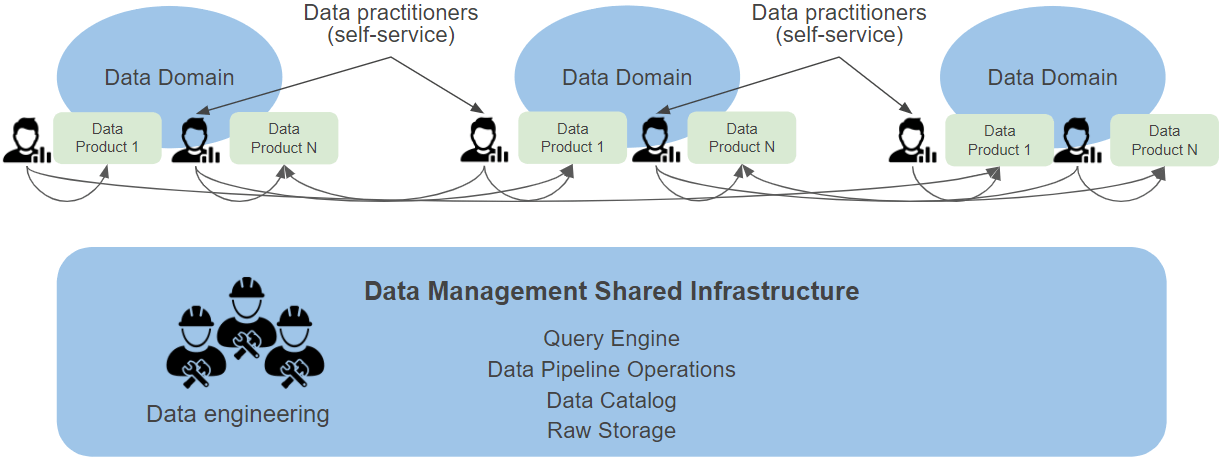
Data product from domain producers and data engineering providing infrastructure
Faster turnaround as individual product requirements are not blocked on central teams.
Better data governance as it stays within the bounded context of its domain.
No more proliferation of bad quality data being cleaned-up by central ETL jobs.
Single source of truth instead of multiple copies of same data. Large enterprises have at times ended up with hundreds of copies of same record across systems.
Definition
While the core definition data mesh as a federated design is established, the structural details especially around distribution of responsibility is not yet standardized across the industry.
Operational
Increased responsibility on application teams.
Overhead of ensuring interoperability across data sources.
Semantic/syntax modeling standards.
Standardize meta-data elements and formats.
Clear guidelines for identifying boundaries of data ownership, especially for shared concerns.
Ensuring consistency is harder in a federated model.
Technology
Lack of full-stack solutions.
Query orchestration engines like Presto can provide a polyglot layer for connecting across multiple, and even heterogeneous data sources. However, its performance is predictable mostly in a homogeneous stack.
With no central data ownership, it becomes harder to debug any quality issues.
Difficult to support scenarios that require cross-domain denormalization for performance or simplification.
Scale
This can lead to proliferation of the types of data sources (Hadoop, SQL, NoSQL, etc.) residing in multiple locations (Data centers, Azure, AWS, GCP etc.), which can lead to performance degradation per query and may require some support for central stores.
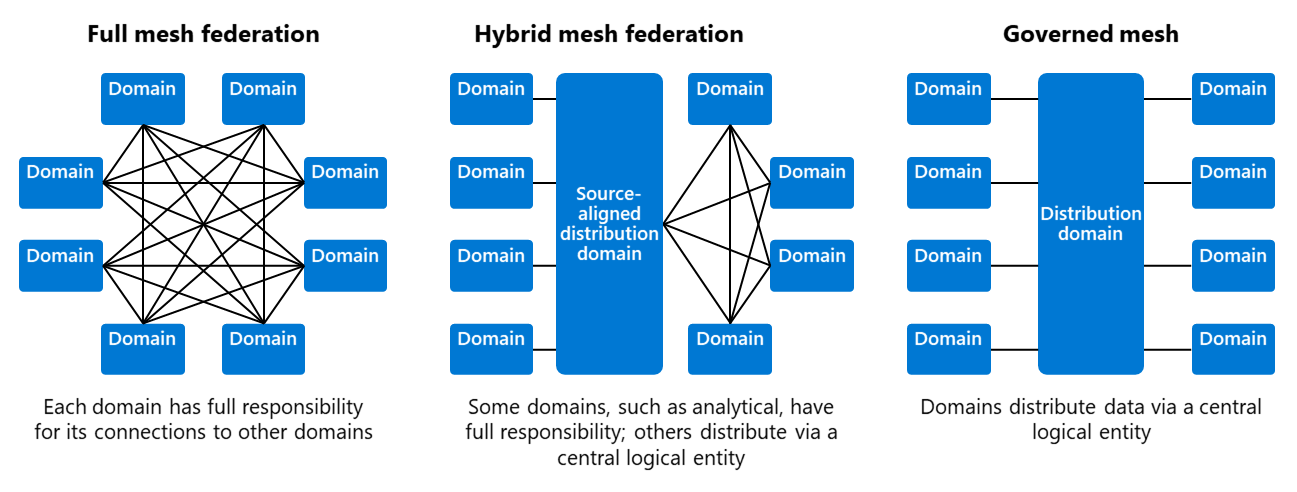
Mesh variants with full federation to full governance (CDR)


Sign up with your email address to receive news and updates from InMobi Technology