

Microservices are almost everywhere, and we are moving towards nano services. Monoliths are things of the past and the world has realized that to meet fast-paced requirements, we need fast-paced development. But it's difficult to achieve that in monoliths because of various concerns like maintainability, scalability, reliability, and slower deployment speed. While the first three concerns are automatically taken care of when you break your monolith into several microservices, but the deployment speed remains the same unless you approach to tackle it the right way.
In this article, we’ll discuss about how to approach faster deployments, or simply speaking Continuous Deployment while working with microservices architecture.
The idea behind the microservices architecture was to segregate responsibilities and manage them separately. The microservices architecture when followed with the right Software Development Methodology can result in faster development of features. But as we start developing features faster, there comes the challenge to deploy them faster. So, not only the development but the entire cycle of code → build → test → release should support it and all the components should work as an assembly line to get things to production faster.
The problem may look easy from the surface but as we dive deep to solve it, multiple hurdles, blockers, and limitations appear. But if started the right way, we could achieve a sub-optimal solution and most of our DevOps practices are currently trying to optimize it, but we are nowhere near it.
Through this blog, I will try to share some of my findings while working on tackling similar problems in our infrastructure. This would be useful for engineers planning to set up their infrastructure for continuous deployment/delivery (CD). We’ll go through the problems we encounter while setting up the CD infra and possible approaches that can be taken to fix them. But first, let's understand what Continuous Deployment/Delivery is and why do we need that.
There are many definitions that define continuous deployment but the one I find most relatable is:
“Continuous deployment is a software engineering approach in which software functionalities are delivered frequently and through automated deployments”.
The functionality is also known as a feature in the software industry where the job of the deployment pipeline is to ensure that the newly developed feature should reach production automatically as fast as possible.
In continuous deployment, we start from the phase where the software has already passed the unit tests (UTs) and integration tests (ITs) and is ready to be deployed in the form of an artifact. Now, one would wonder if an artifact has already passed the UTs and ITs, can we still face any issues during its deployment, and does it require more testing? We will try to find an answer to this question in the next section.
Let’s discuss the various problem we might face while setting up a Continuous Deployment assembly line aka Pipeline for software delivery.

A perfect product is always a result of a perfect test environment. The better the testing infra, the better chances of having a non-faulty feature. We often fail to create these test environments and hence witness a lot of faults and breakdowns in a released feature.
The mindset here is to run the feature with tons of UTs and ITs with a higher percentage of Branch and Code coverage. But code testing is the first line of defense, and the actual testing will only happen once the feature goes into a highly scaled infrastructure where it will be bombarded with millions of QPS.
No testing is sufficient enough and can guarantee the perfect feature but that doesn’t mean we shouldn’t invest in a proper testing infra. On the other hand, the testing should also be confined within specific time limits. Long testing time can result in delayed delivery of features and sometimes might lose their value.
We should define the testing infrastructure smartly so that the feature can be tested on all the scenarios before it reaches full deployment. So, the principle of “Quality over Quantity” is most appropriate here.
Today, Cloud is the most popular deployment infrastructure for most services, and for a highly scaled service the deployment destinations could be in the order of thousands of pods scattered across multiple deployment regions.
To support this highly scaled deployment, the pipeline has to deploy in all these deployment regions which takes time, and one can’t mark the pipeline as successful unless the deployment to all the regions has been completed.
So, we should define our strategy in such a way that the deployment is done in a phased manner rather than targeting the complete infra at once.
The pipeline should be a short-lived process and it should not run for a longer duration. The pipeline consists of multiple stages starting from testing to deployment. If we optimize the former stages, the deployment stage might still take time because of the extra overhead a service takes while getting started. Some services may need to create connections with databases, pre-populate caches, and pre-compute frequent resources. This pre-processing takes time resulting in a long wait for marking a service as started. Now, consider a scenario with a highly scaled service where the start time of a service is significantly high then the total deployment time can easily vary from a few minutes to hours.
Services with higher deployment time can result in slower deployment cycles and can block multiple deployments waiting in queues. One can ask an obvious question why we can’t just throw in more resources to run more pipelines in parallel and regardless of how long the deployment time is, the extra resources can deliver more features easily. But more resources do not always solve the problem. The production deployment mostly targets one at a time to avoid conflicting features and even if we throw in more resources that will be of no use in the case of sequential pipelines.
Once a feature is deployed, we might still face some problems and breakdown can occur anytime. There are two most acceptable solutions once a service fails in production: Roll Forward or Roll Back. The Roll Forward basically means fixing the problem and then deploying the fix from the same deployment pipeline. The Second option is to roll back the change where the newly deployed feature will be rolled back, and the pipeline will deploy back the previous running version of the deployment.
Though it sounds like a logical step and easy to implement but the question is why is it a problem in the deployment pipeline? So, let's understand a scenario when a pipeline successfully released a faulty feature in production. Now, our system detected the problem where the feature is not behaving as it was supposed to, and you decided to move to either roll back or roll forward. But there may be a possibility of a pipeline already running to release other features in the production. The automation will have to detect this and halt that pipeline and start the new release pipeline carrying the fix for the faulty feature.
Also, we need to maintain the information about the last successful release version of the deployment so that in case of a Roll Back the pipeline can trigger the deployment of that version.
So, the above-mentioned problem is one such example but there are other complexities that arise while implementing Roll Back/Roll Forward.
The CD setup may sound easy but that does come up with multiple problems and complexities. I mentioned a few of them in the previous section. Does that mean the setup is difficult? Does that mean we can't achieve it? The answer is NO. We can still achieve it by following some standards and measures that can reduce the complexity and lead to a seamless solution. Having said that, we should also keep in mind that our practice could differ for different use cases and there is no one solution that fits all. The approaches should vary depending on the system, service, and infrastructure.
In this section, we’ll discuss the different standards and measures that could be followed to achieve a seamless pipeline for continuous deployment.
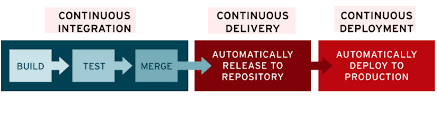
The one common mistake we do is to intertwine the CI and CD processes. The job of the CI process should be to Build the software, measure Code and Branch Coverage, run UT + Regression testing of the code, and at last, generate an artifact that is ready to be deployed (Continuous Delivery). The Job of the CD process is to take this artifact and run it through various real-time testing environments and then release it to the different production infrastructures.
If we try to combine the CI part with CD then we often run into the problem of requiring manual inputs at various stages which might defeat the idea behind a complete automation of the deployment process. The segregation of responsibilities from the very start can lead to a better solution.
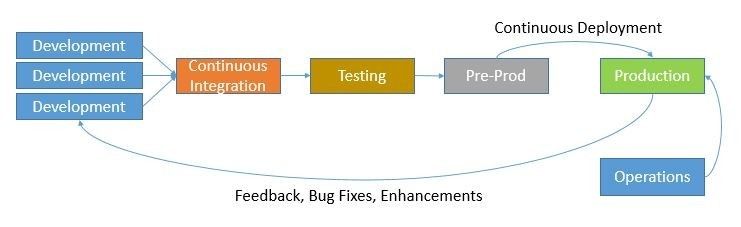
The UTs and Regression are definitely required when testing your code for a feature but simply based on this testing we should not mark our artifact as ready for deployment. The feature should also be tested in an almost production scenario. The non-prod/pre-prod infrastructure setup can provide that environment.
Every service should have a pre-prod infra imitating almost the production environment. The infrastructure should support some dummy requests to the service till the point of a non-prod setup of a storage layer. This pre-prod setup should be a mini version of the production setup which could be an always-running setup, or an on-demand setup depending on the time taken to create it.
The newly produced artifact should run on the pre-prod setup before sending it to production and should be verified that it's behaving as expected. The setup does require a one-time investment, but it reduces the chances of deployment of a faulty release in production. Also, it could easily be automated to reduce the testing time.
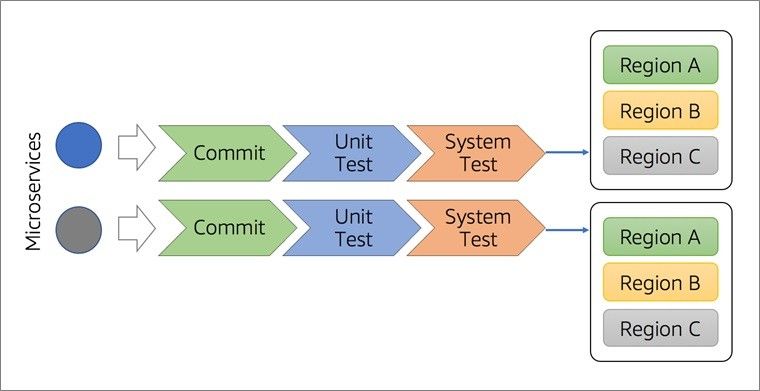
As we discussed in the problems section, a highly scaled service may have multiple deployment regions that take time to mark a deployment pipeline as successful. A case may arise where a service was successfully deployed in one region but failed to be deployed in another due to some issues in the network. Re-running this failed pipeline will again start the deployment in all the regions.
The problem can be avoided by implementing region-based deployments in the deployment pipeline. In the case of region-based deployment, a failed deployment in a region can be retried without touching other deployment regions. The region-based segregation can also help us identify the faulty region and we can put in efforts only to fix the problem there.
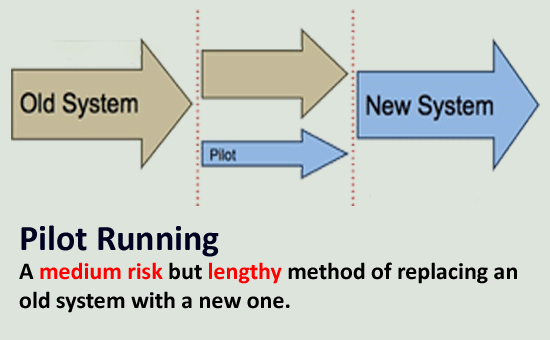
The pre-prod testing can help identify most of the problems in a faulty feature but in an ideal world, the testing can't cover 100% of the cases. We still haven’t tested the feature in real-time production scenarios and releasing a feature simply based on the feature testing could still break in production.
The Production pilot is a way to test your feature in a production environment where a feature-in-test will be deployed in a small percentage of a production setup and will receive actual requests over the internet. We call that small percentage of the production environment a Pilot Environment.
The new version of the service will be deployed in the pilot and will be monitored for some time to verify that the deployment is not causing any problems. Once the verification is done, we release the service to production.
The process can be bundled with any of the deployment strategies: Canary, Rolling, or Blue Green. After a successful pilot, we can use any of the above-mentioned deployment strategies to release the feature.
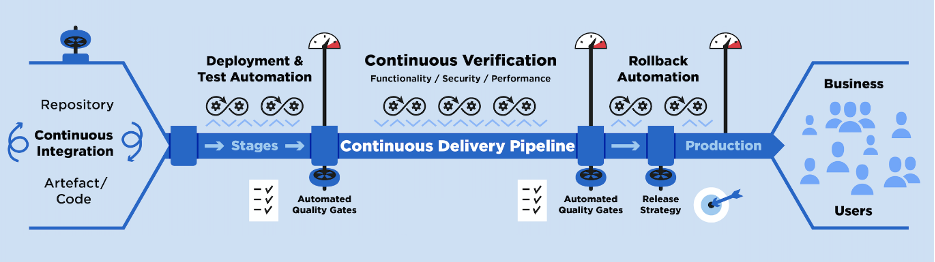
Continuous verification is also emerging as a fundamental approach for creating an automated pipeline for continuous deployment. As discussed before, we should be able to verify the Pilot or pre-prod deployment to check its sanity. This could be a manual process, where one has to continuously monitor the behavior after deployment, or we can implement automation around it. The automation for developing a verification setup for a continuous deployment pipeline is what we term as Continuous Verification.
The service with the new feature is deployed in the Pilot and the Pilot environment will be monitored through a monitoring stack where any deviation of the Pilot environment from the actual production will be reported and the decision to Pass/Fail the Pilot will be derived based on the deviation percentage. If the Pilot and the production monitoring metrics are aligned, then we can mark the pilot as passed or else failed.
Proper implementation of a continuous deployment pipeline can result in faster delivery of a feature but can often result in a faulty release without an Observability stack in place. The service should always be monitored during a deployment pipeline and an alert should be raised for any unwanted behavior so that adequate precautions can be taken before sending a faulty release to production.
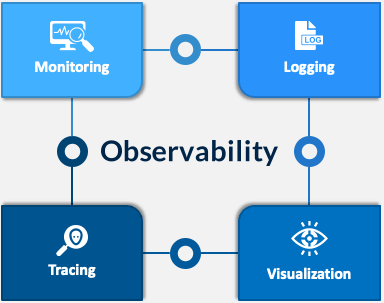
The Observability stack is often used for post-deployment monitoring but the same can be extended for the verification of the pilot and pre-prod testing. This can detect some of the feature faults early and help in reducing the chances of deploying a faulty feature.
Extending from the Continuous Verification – which is done after the pilot and before the production deployment – we may still encounter problems when the feature is deployed full-scale on production. Sometimes, the problems are pretty evident and can be identified soon after the production release.
The post-deployment verification runs for a fixed duration even after the full deployment and monitors any anomaly in the new feature. In case the verification system starts encountering problems after deployment, the pipeline can roll back the feature and deploy the last sane version of the service.
This verification can reduce the time to manually roll back the feature by rerunning the complete pipeline with the fix in case of a faulty release, which could even be automated avoiding any manual intervention.
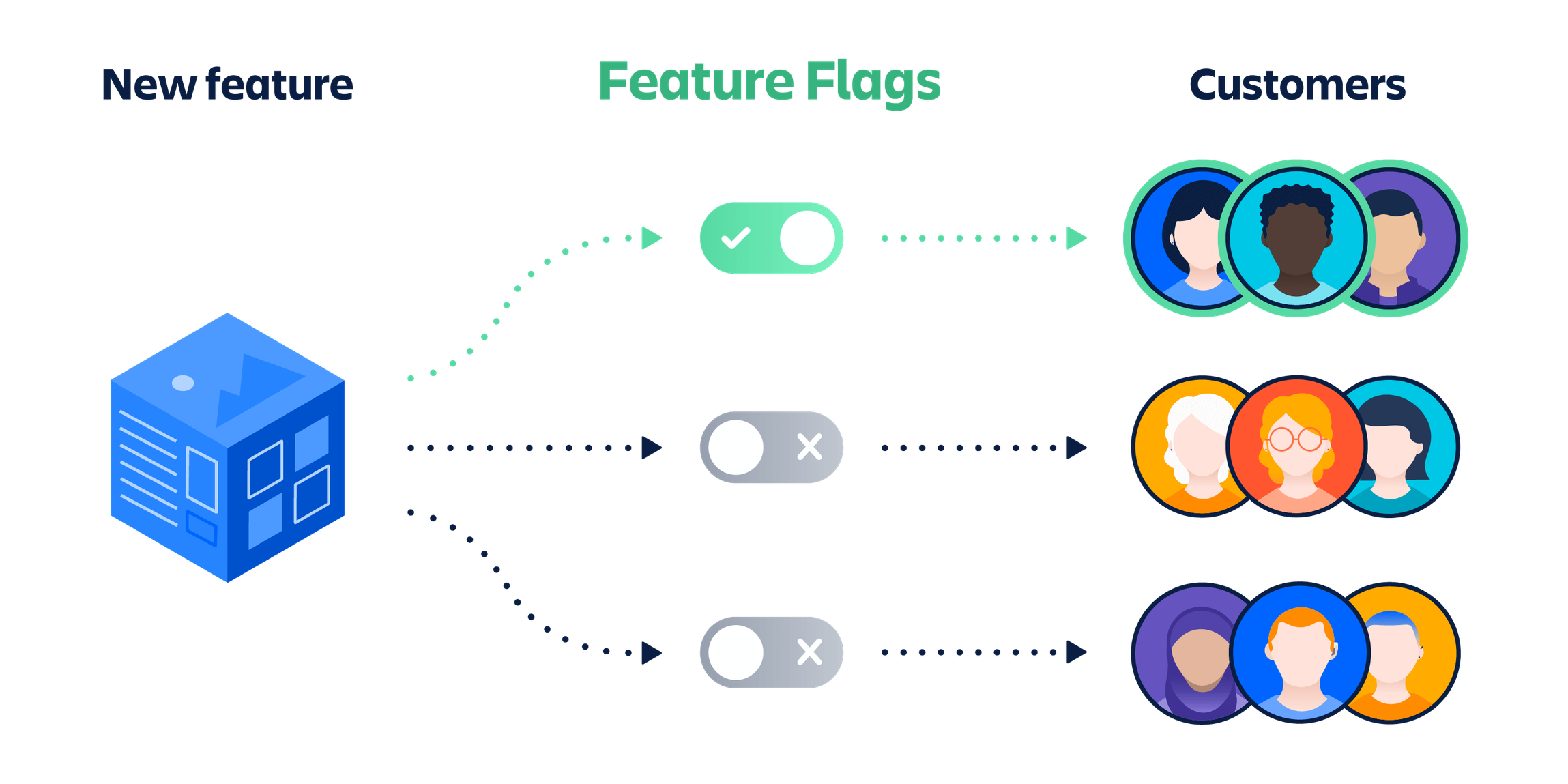
The concept of feature flags has been adopted by many organizations and developers are using this pattern in their development style to develop a feature under a feature flag. This can be used for controlled delivery of service but can also be useful to recover from a faulty release.
If we release a service with a set of feature flags and the new feature causes some issues in production, then we can simply disable the faulty feature flag and the service will not need to be rolled back or forward.
So far, we discussed on what all the different strategies we can apply in our deployment pipeline to release a service without fault. But all those strategies may not work at all (or could be very difficult) if we choose a tool that does not support the creation of such pipelines.
Choosing/developing the right tool will definitely help us achieve what we keep as a goal before starting setup for continuous deployment. Most of the tech giants have developed their own in-house tools for creating a solution that fits into their deployment architecture. But we still see some companies investing more into third-party tools as they feel the offering is suitable for their use case.
There are plenty of tools present in the current market claiming one is superior to the other. So, we should spend some time analyzing our requirements and the tool that is close enough to fulfill those requirements without much of a hustle. If you don’t find any suitable tool, get yourself ready to create one in-house and you never know if the same could be open-sourced or licensed in the future.
Continuous deployment is the need of the hour, and all the tech companies are trying to achieve the same by using external offerings or developing solutions in-house. In any case, the solution may not be as helpful as expected unless we follow some standards or measures while implementing it.

There is no perfect system and not a single solution will serve all the use cases but there are some fundamentals that can be used to make a pipeline near-perfect.
In this article, we discussed various measures that can be taken while implementing a deployment pipeline so that we can reduce the chances of delivering faulty software.
The system is evolving at a very high pace and the solutions that are working today may become obsolete in the future. So, our deployment strategies and solutions should also evolve over time to compensate for future service architectures.


Sign up with your email address to receive news and updates from InMobi Technology