

Pseudonymization is a technique where you replace real ids with corresponding pseudonym ids.
This is done while storing personally identifiable information (PII) for the following reasons:
When the pseudonymized data no longer contains the actual user ids, it could easily be exposed to internal or external teams.
Since the data is pseudonymized, you avoid the risk of people peeking at the actual user ids.
If the data is leaked out, then the risk of PR fall is minimized.
This is one of the recommended ways suggested by GDPR.
Pseudonymization is mostly performed using the following ways:
Maintaining an offline pseudonym table.
Maintaining an online pseudonym table.
Using a reversible key.
| Pseudonym Table (B) | |
|---|---|
|
User id 1 |
Pseudonym id 1 |
|
User id 2 |
Pseudonym id 2 |
|
User id 3 |
Pseudonym id 3 |
|
User id 4 |
Pseudonym id 4 |
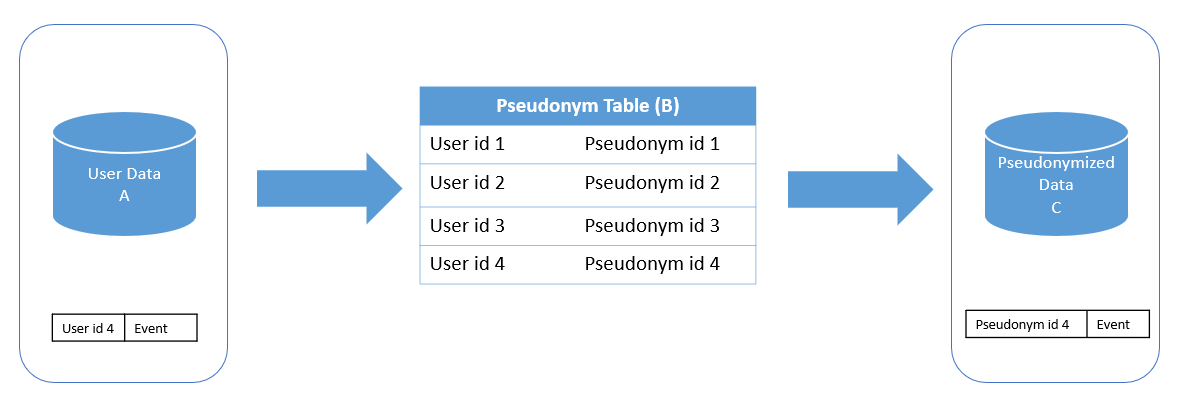
We take the Data Stream (A) and join it to the Pseudonym Table (B) replacing the User id with Pseudonym id in the Pseudonymized Data (C). There are two cases to consider here:
If the user id already exists in the table (B), then we use the pseudonym id as an identifier in the final table (C).
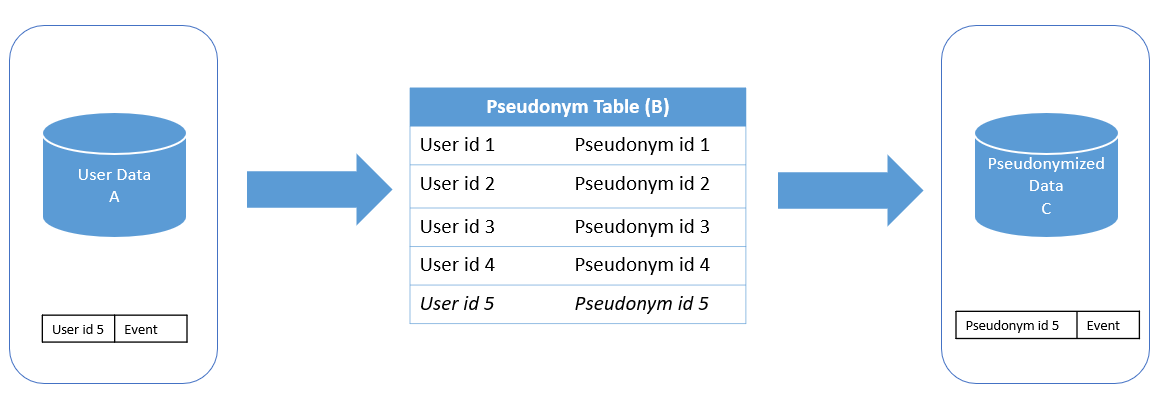
If the user id is new and doesn’t exist in the table (B),
We create a new entry of (user id, pseudonym id) pair and insert into the Pseudonym Table (B)
We replace the user id with the newly created pseudonym id (from the previous step) and place the event into final table (C).
If we get a row bearing User id 4 that already exists in table, then it’s replaced by Pseudonym id 4.
If we get a row bearing User id 5 that doesn’t exist in the table, then a new entry User id 5 is added to the Pseudonym id 5.
We need to forget every information concerning the user. The data of the said user shouldn’t be used anymore in the system.
Let's assume that we receive a request to forget User id 3, then we erase the id from the pseudonym table. The table will become like the one below:
|
User id 1 |
Pseudonym id 1 |
|
User id 2 |
Pseudonym id 2 |
|
User id 3 |
Pseudonym id 3 |
|
User id 4 |
Pseudonym id 4 |
|
User id 5 |
Pseudonym id 5 |
Let's assume that we have an RTA request for User id 2, then:
Visit the Pseudonym table and find the associated Pseudonym id 2
Using Pseudonym id 2 visit the table (C) to find all the relevant information of the user and return it.
The RTFs are quite easy to implement. Simply remove the entry from the pseudonym table, and it's done.
The Pseudonym table grows humongous in size.
Since we began the entries have grown from 3 billion to 14 billion. Within a year it's expected to have 30 billion entries.
Its data size has scaled from 350 GB to 900 GB.
The job to pseudonymize has become too expensive to handle with a majority of it attributed to the supply side platform and data ingestions for the central platform.
The Join in the table is very error prone.
On multiple occasions we have lost the pseudonym table due to job failure. We are even keeping a backup table to mitigate this issue.
By the time the error is detected, the users coming into the system will have different pseudonym ids, which requires a very expensive cleanup of the data. At times,
We spent 2 months figuring out the bug in the system.
We performed an extensive month-long cleanup activity.
This job has a very high operational overhead.
The pseudonym table has become a single point of failure for the entire system.
This can't be used for online jobs (i.e., cosmos DB lookups). Since the table is presently offline, you can't use it in real-time as the latencies are impossible to deal with.
Maintaining an online pseudonym table is exactly similar to the offline store. The table will be available online instead of being offline.
Lookups will be fast.
Pseudonymization jobs will not become the single point of failure. If a job fails, then the underlying table doesn’t screw up as the table on the online store is intact.
This can even be used for online jobs and also as pseudonym jobs.
The job proved to be too costly for migrating our supply side platform with estimates ranging in tens of thousands of dollars.
Even though lookups are fast, but still there is a lot of complexity in calling the online store.

If you observe the above diagram carefully, there is no pseudonym table in the diagram.
We use a reversible key to pseudonymize the data.
If we replay the key, we get the original id.
This key will be stored in a key vault where no one will have access to it.
Let's assume that we receive an RTA request for User id 2, then:
Using the Reversible Key get the Pseudonym id 2 and visit table (C) to find all the relevant information of the user and return it.
Using Pseudonym id 2 visit table (C) to find all the relevant information of the user and return it.

Take the pseudonymized data.
Use a reversible key to de-pseudonymize the pseudonym id.
Apply RTF – remove the users who have opted-out.
Export the data.

We look around the Pseudonymized Data (C) and delete all the records of the concerned user.


Sign up with your email address to receive news and updates from InMobi Technology