

Airflow is a widely used ETL (Extract, Transform, Load) workflow orchestration tool, used in data transformation pipelines across the cloud world. While working with big data and a lot many data pipelines, we need to scale an Airflow cluster to a limit where hundreds of Spark jobs are running on a scale of hundreds of executors consuming huge resources that can cause bottlenecks on workers. These jobs need to run on cluster mode and requires a compute cluster to carry out the job.
For this we came up with a distributed, scalable, and robust architecture that segregates orchestration and compute while handling communication between them. The solution should be able to handle a larger scale than we typically use.
The segregation will also help in using different orchestration systems with compute as the responsibilities are distributed between both systems, for example Azure Data Factory and Airflow with Yarn or Databricks.
Let's have a fair idea of the scale that we are discussing here.
100s of Spark jobs distributed amongst different teams running every hour.
Each Spark job requires a range of 100-500 executors.
ˀHeavy executors that can go up to 32GB memory and 8 cores.
The above parameters were specific to our work. The solution although should not be limited to these and could even be scaled for a larger number of executors, with higher or lower configurations as well.
Since a heavy job with hundreds of executors cannot run on the client mode, a dedicated compute cluster is required.
The Airflow Spark operator needs to be configured to submit jobs to a remote compute cluster.
Submission of jobs from the Airflow cluster to multiple compute systems.
Airflow should still manage the lifecycle of applications and show consistent results on the UI.
Auto Scaling of underlying compute system.
As we already discussed, applications of this size cannot run on a local Airflow, so we need to come up with a design of decoupled orchestration and compute.
The design that worked for us uses Airflow for orchestration and Yarn for compute and a Cluster Manager in between negotiating among the two components.
The following are the components of the new architecture:
Airflow: This component handles the orchestration and keeps track of the life cycle of the applications (a few lightweight tasks can still run on the workers locally). We used Celery executors hosted on Kubernetes and Redis as broker. There may be multiple Airflow clusters in a single setup that could submit applications to multiple compute clusters.
Yarn: This component is the compute part of our setup and takes care of running Spark jobs. It's a Yarn cluster hosted on Kubernetes, with its node managers on VMSS. There can be multiple Yarn clusters in a single setup receiving applications from various Airflow clusters.
Cluster Manager: This component is the negotiator between compute and orchestration of our system. It contains information about all the clusters, and also takes care of submitting jobs from a particular Airflow cluster to the respective Yarn.
Livy Server: Apache Livy is a service that enables easy interaction with a Spark cluster over a REST interface. One Livy server is tied to a single Yarn cluster. Upon receiving a job for submission to a specific Yarn cluster, the Cluster Manager reaches out to the respective Livy server to send it.
Autoscaler: It takes care of scaling up and down the node-manager VMSS based on the requirement and uses Azure APIs to do so. This will help in dealing with heavy applications.
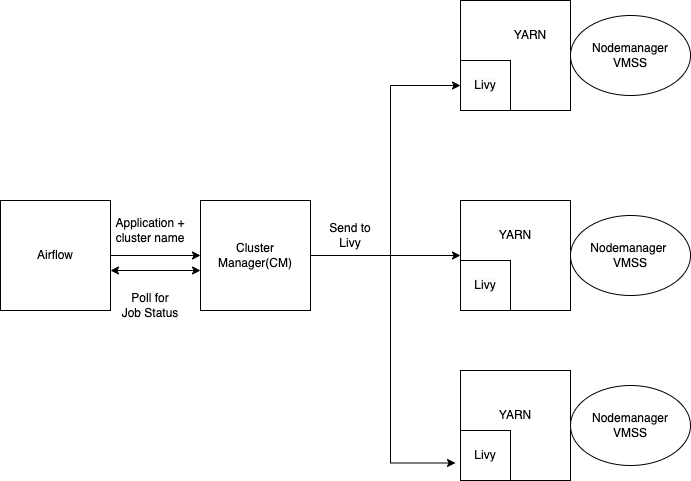
Let's dive a little deeper into the above architecture and understand the flow of a particular DAG once it’s triggered by Airflow.
Airflow submits a job to Cluster Manager with information like Spark configs and the cluster name.
The Cluster Manager fetches the Livy server details of the particular YARN cluster and then submits the Spark job.
Livy converts the Spark configs forwarded in the request body into a spark-submit command.
Livy contains the config of the Yarn cluster it is tied to, and with its help it runs the command to trigger a job on a specific Yarn cluster.
Autoscaler reads this value of required resources from the Resource Manager and scales the VMSS to get resources to run the job.
Once the Resource Manager gets the required resource it goes ahead and initiates the job.
In the background, the Airflow worker keeps polling the status of the running job to update the DAG running status on the UI.
To submit a job from the Airflow to Spark we need to build a plugin that can do so. The duties of this plugin are as follows:
This plugin has all the attributes of the Airflow Spark operator.
It generates a request body containing all the Spark configurations.
Submits the request body to the Cluster Manager with the cluster name and receives the application_id as a response.
Poll the Cluster Manager for the status of an application.
Since we are working at a high scale, we also need the compute to be scaled up based on the requirement. Having those many VMs static will impact the cost and needs aggressive dynamic scaling. Hence, we built an autoscaling solution for it.
Autoscaling work in the following steps:
Whenever an application is submitted to Yarn, the Resource Manager publishes metrics to Graphite.
Autoscaler runs timely profiles which queries Graphite to get the required V-Cores and Memory.
Based on requirement, the Autoscaler calculates how many instances of VMSS of a particular SKU type are required.
Autoscaler makes a call via the Azure API to increase the number of VMs for a particular VMSS.
Once the VMSS are scaled up, the node-manager service is initiated on them.
These node managers will be registered with the Resource Manager and can be used for running jobs.
Autoscaler queries the Resource Manager to get nodes that are completely free.
Autoscaler removes all such nodes.
The reason behind removing only free nodes is to avoid job failures, as we don't want to remove such nodes on which anything is running. Although, we have implemented a greedy scheduler on Yarn so that at first, we fill the most used node managers that ensures that free nodes are quickly available to scale down.
We also built a Cost Management dashboard to calculate the cost of each running DAG. This is calculated based on the required resources and run-time of the application. Although, it's not exactly accurate but can give a rough idea of the application cost over time.
This dashboard provides a picture of the cost of each DAG changing over time. The increase or decrease in costs could be attributed to the input with respect to time or any specific VMSS-related issue, like Spot node eviction. Also, it can help in figuring out how to run a job more effectively by fine-tuning.
To summarize, the architecture helped us achieve the large scale of resources for the applications we run effectively in a more distributed manner by allocating the responsibility amongst Compute and Workflow managers, and also segregating the resources amongst different clusters by creating different services and writing a few plugins. It also helps in controlling cost by aggressively scaling VMSS as well as providing an idea about the application cost which can help in performance enhancement.
This is an older success story of ours and we have eventually moved on to an alternate solution based on changing requirements. Hope this helps you with some valuable insights in your specific use case.
Happy reading!


Sign up with your email address to receive news and updates from InMobi Technology