

Presto is an open-source distributed SQL query engine that enables fast querying and analysis of large data stored in heterogeneous sources, including data warehouses, databases, and cloud storage platforms.
InMobi uses Presto to analyze large volumes of data from various sources, including Azure Blob storage and a Postgres database to generate reports and gain insights into the performance and effectiveness of its mobile advertising campaigns.
Before embarking on its cloud journey, InMobi was using Apache Lens for its data processing needs.
Apache Lens is an open-sourced unified analytics platform that enables users to perform SQL and complex, multi-structured queries on data stored in a variety of sources, including data warehouses, databases, and cloud storage platforms.
Apache lens internally uses MapReduce tasks to meet data processing needs. All these MapReduce jobs were running on premise machines.
In 2019, as InMobi onboarded Azure for its cloud needs the team recognized the need to explore other data processing engines that could meet its future demands while keeping costs under control. With the increasing volume and complexity of data that InMobi was dealing with, it was important to have a data processing engine that could handle large volumes of data efficiently and effectively.
After evaluating various options and carefully considering the costs and benefits Presto was selected as the query engine for all of its heavy reporting use cases over Apache Spark and Hadoop.
Primary consideration for choosing Presto:
Better SQL query latencies as compared to Spark during the POC.
Presto ability to query data from multiple sources in a single query.
Better placed than Spark for processing multiple TBs of data.
At InMobi, we follow the star schema for our tables to optimize query performance in Presto. Here, a large central fact table is surrounded by smaller dimension tables.
Currently, our data is stored in the Parquet format on Azure Blob, and we are exploring the use of Delta format as well. By using the Delta format, we hope to be able to further improve the performance and reliability of our data processing operations.
In our data processing operations table sizes can vary greatly ranging from 1 GB to 700 GB per day. The normal query pattern for these tables typically involves people querying data from the last one day, the last week, the last month, and sometimes even 2-3 quarters. This wide range of table sizes and query patterns involving joins can present challenges for optimizing query performance in Presto.
We have containerized our Presto service and are using Azure Kubernetes Service (AKS) to deploy it.
We have used two user node pool in our Kubernetes cluster:
Coordinator Node Pool (VMSS): The Presto coordinator service is deployed here with a configuration of 8 core, 64 GB.
Worker Node Pool (VMSS): The Presto worker services are deployed here with a configuration of 16 core, 128 GB.
The Hive metastore service is used to store the metadata of the data stored in the Azure Blob.
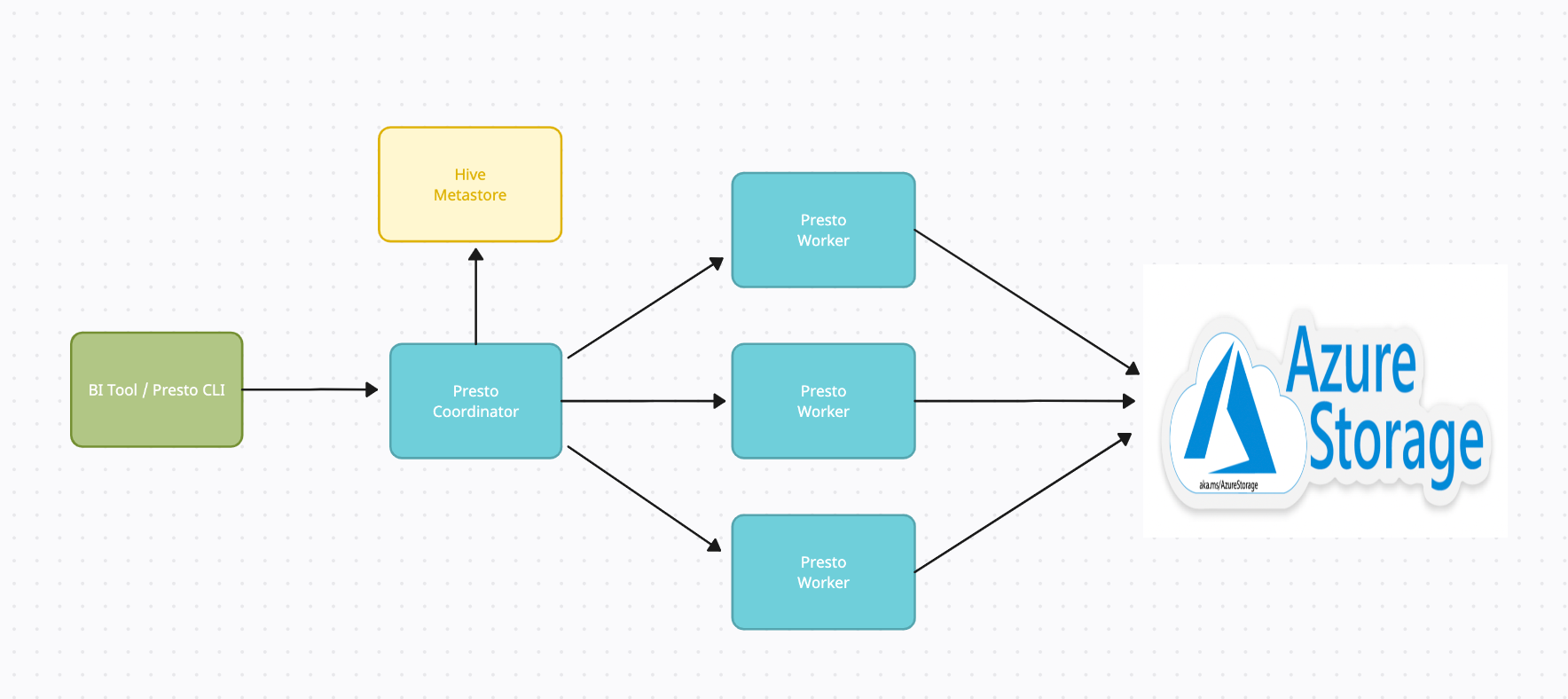
Each worker pod is deployed on a separate virtual machine (VM) within the worker VMSS. We use the Helm package manager to deploy and manage our Presto deployment on AKS. By using Helm to deploy Presto, we can easily automate the deployment process and manage the configuration of our Presto deployment in a consistent and repeatable way.
All the configuration information regarding the coordinator and workers are passed as configmaps to the coordinator and workers deployments.
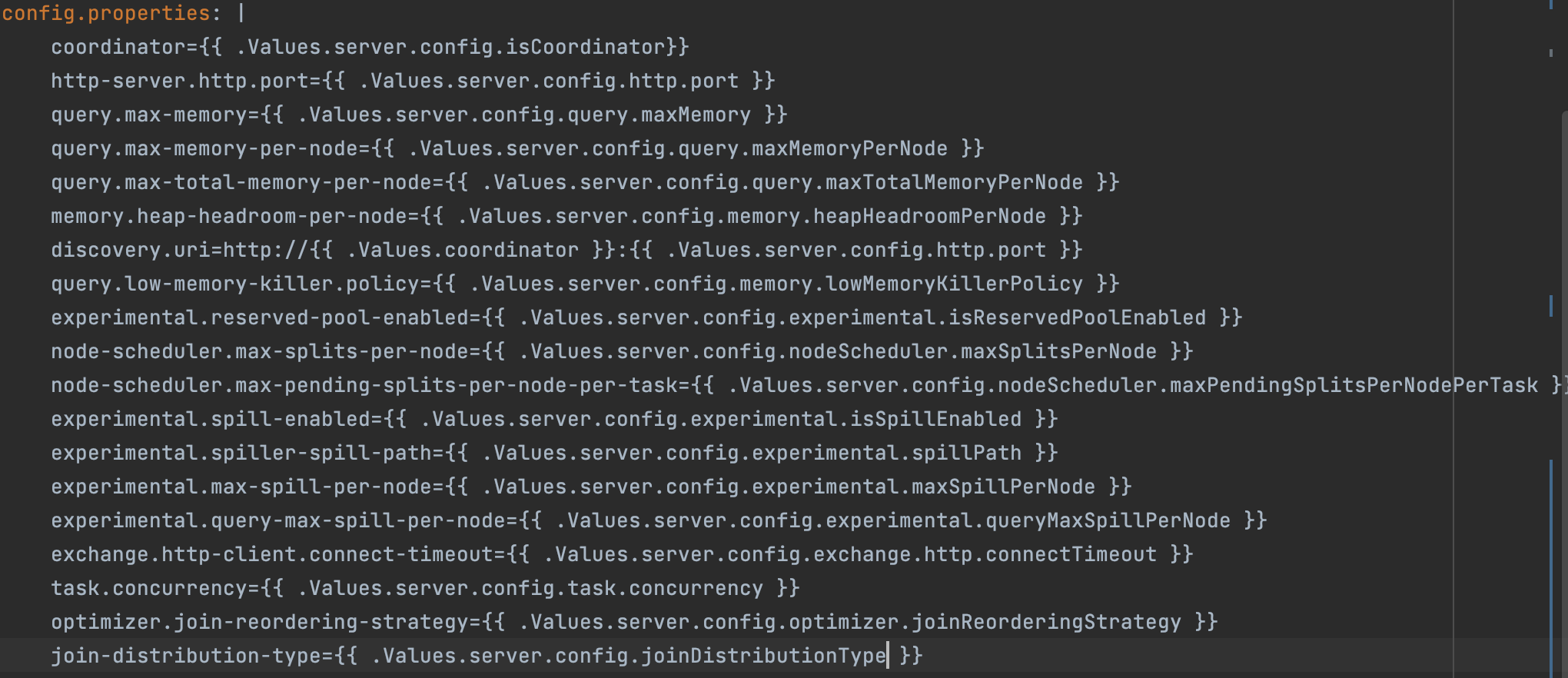
For storing storage secrets and DB passwords, we use Azure secrets.
Presto metrics are exposed at port 9000, using jmx_prometheus_javaagent jar and metrics are filtered using configmap.yaml.
We use Prometheus for metrics collection using service monitor and Grafana for metrics visualization.
For logging, we use standard ELK setup.
For registering UDFs we use a separate repo where all UDFs are defined and registered on Presto server.
We are using the Kubernetes autoscaler to horizontally scale the number of worker replicas based on the CPU and memory utilization of the worker pods. By setting threshold values for these metrics, we can ensure that the autoscaler will automatically add or remove worker replicas as needed to maintain optimal performance.
In addition to scaling based on CPU and memory utilization, we have also implemented autoscaling logic based on the number of queries being run on the Presto cluster. We use Prometheus to pull metrics on the number of running queries and use this data to trigger the autoscaler to add or remove worker replicas as needed.
As most of the queries query large amount of data (TBs), on an average a query runs for about an hour while the maximum query time during the day is around 4 hours.
AKS had a default toleration of 10%. So, if our target metrics are outside this range autoscaling triggers. For instance, if our target utilization for CPU metric is set to 70%, if our target utilization drops below 63%, it will scale in and above 77% it will scale out.
Frequent scale-in (removal of workers) operation could lead to failure of queries due to removal of worker node on which a query was running.
Azure VMs takes ~ 5 minutes to start a new VM in case of scale out (addition of workers).
To overcome query failures due to AKS scale-in (removal of workers), we added the support for graceful shutdown for our Presto worker pods. It prevented the termination of worker pods on which queries are running in case of scale in. During graceful shutdown, worker pods won't be accepting new requests but will continue to complete existing running tasks.
To prevent frequent scaling in and scale out of worker pods, we have added two scaling approaches:
Scale out approach where CPU target is 70% and the scale down policy is disabled.
Scale in approach where CPU target is 50% and the select up policy is disabled.
The above two approaches ensure to add the resources when CPU metric crosses average utilization target of 70% and remove nodes when the average utilization goes below 50%, helping us maintain a broad range of acceptable metrics.
Optimizing Presto performance can be challenging as it often depends on our query pattern and usage.
Selecting the VM may have a significant impact on query performance as well as failures. The number of cores, memory, disk IOPS, or disk limit could be the criteria here.
Partitioning on frequently used columns, right data model (star schema), right join key etc.
At InMobi, we have tuned Presto to optimize its performance for our specific query patterns and workloads. This involves adjusting various parameters within the Presto configuration to suit our deployment needs.
query.max-memory-per-node - The maximum amount of user memory a query can use on a worker.
We increased it to prevent query failures due to insufficient memory.
query.low-memory-killer.policy - Selects the query to kill when the cluster is out of memory.
Set it as per your expectation.
join-distribution-type - The type of distributed join to use:
Since we were following star schema and most of the dim tables were less than 10 MB in size, we have used the BROADCAST JOIN as our join-distribution-type.
Using BROADCAST join instead of Automatic join (with no table stats) reduced the latency of some of our queries by 80% along with significant reduction in overall cost.
optimizer.join-reordering-strategy - This is the join reordering strategy to be used. We use the automatic join-reordering-strategy.
experimental.spill-enabled - Spilling memory to disk to avoid exceeding memory limits for the query. We prevented join failures for some of the queries, but it significantly increases the query latency.
node-scheduler.max-splits-per-node - The target value for the number of splits that can run for each worker node. It should set as per query pattern and keeping in mind splits are balanced across workers.
We are currently evaluating Presto cache and other storage layer optimizations on our Presto cluster.
Looking forward, InMobi will continue to explore new and innovative ways to optimize the performance of its Presto deployment and leverage the power of big data to drive business success.
By staying at the forefront of data processing technology, InMobi can ensure that it's able to deliver the insights that its clients need to succeed in an increasingly data-driven world.


Sign up with your email address to receive news and updates from InMobi Technology