

CI/CD for streaming jobs can be achieved by using tools like Harness and Jenkins to automate the build and test phases and automate deployment to a streaming data processing system such as Apache Flink, Apache Kafka Streams, or Apache Spark Streaming. The goal is to help developers quickly iterate on their code changes and safely deploy them to production with minimal downtime or risk of errors.
The first entry point of data in the architecture is the EventHub which is consumed by the Spark Streaming job and is written in the form of a Delta Lake table.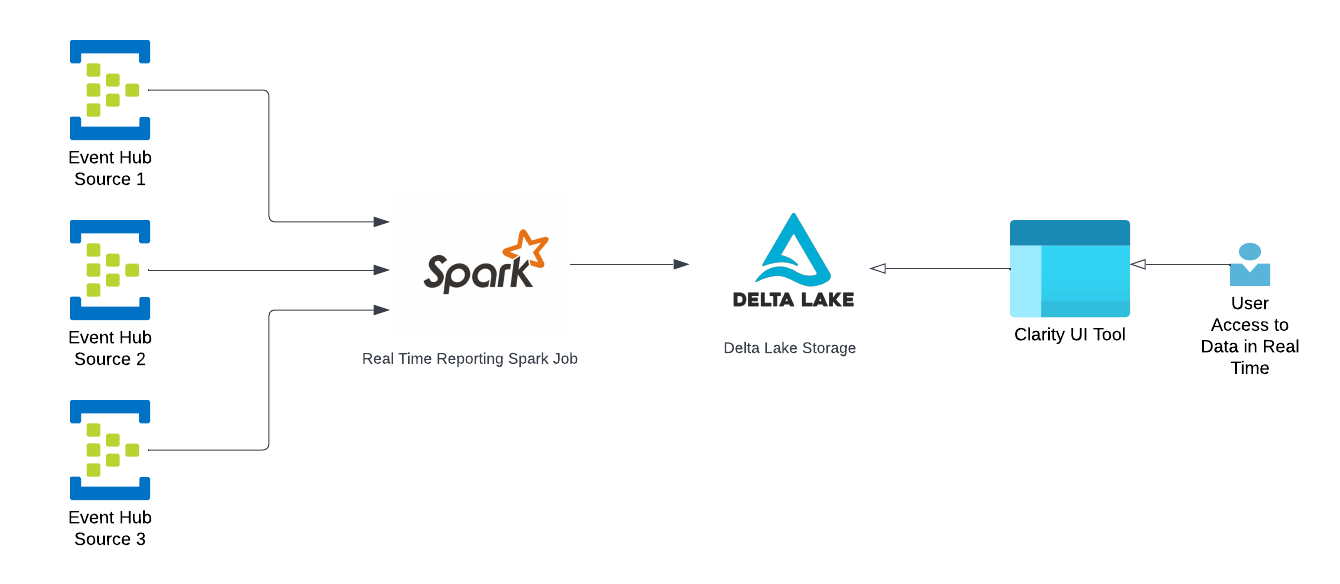
Spark Structured Streaming
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. The Spark engine will run it incrementally, do the transformation, join all the data from all the sources continuously, and update the final result as streaming data continues to arrive.
Delta Lake
Delta Lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. We can store our data the way it is, without having to structure it first and run different types of analytics from dashboards and visualization to big-data processing and real-time analytics.
Regression testing ensures that the best version of your product is released. Considering continuous deployment with Spark streaming, it's very important to have a high confidence in the job and ensure the measure calculated/generated are as expected for all the different source streams with the transformed data.
It increases the chance of detecting bugs caused by changes and also makes sure all the output generated from the input set matches the actual result.
It can help catch defects early and thus reduce the cost to resolve them.
Helps in researching unwanted side effects that might have occurred due to a new operating environment.
Ensures better performing software due to early identification of bugs and errors.
Most importantly, it verifies that code changes do not re-introduce old defects.
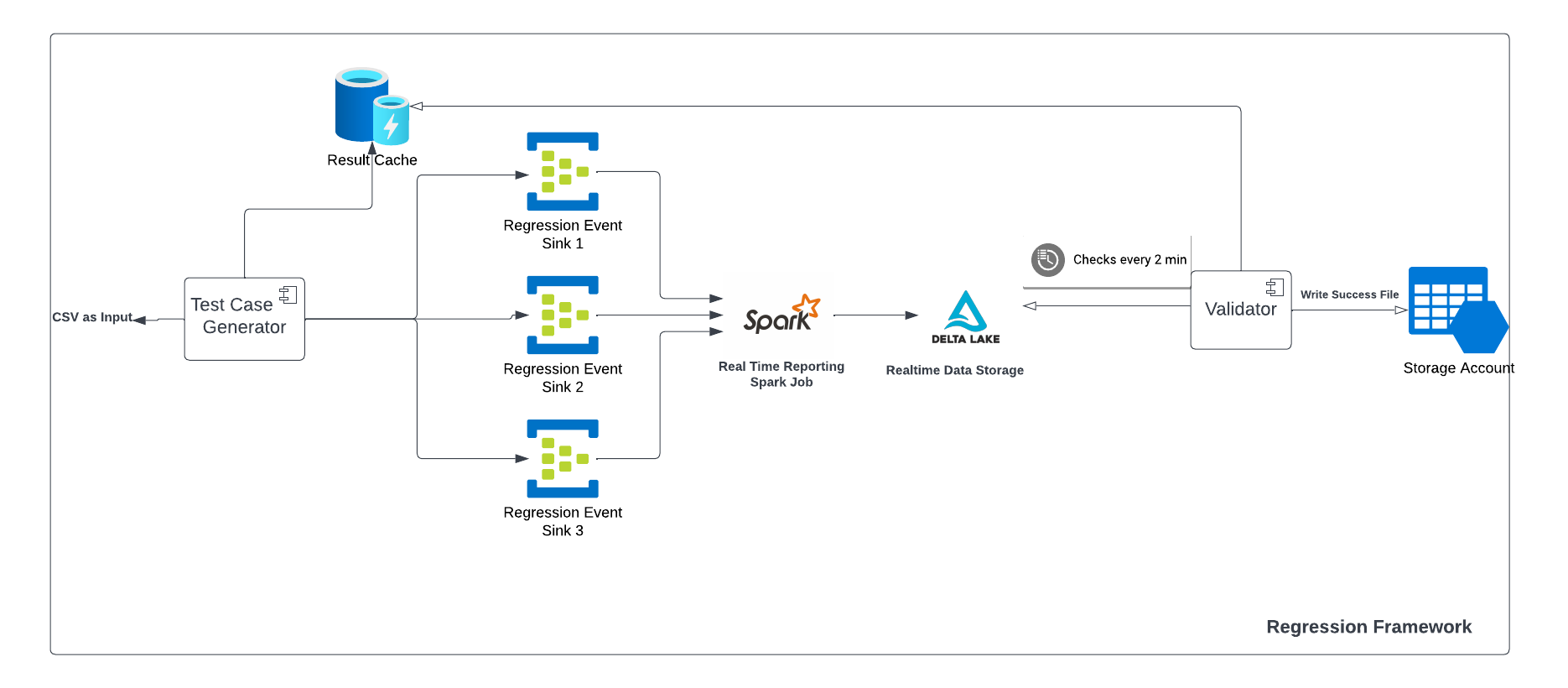
Let’s take a look at the different components.
Its purpose is to generate the test case that enriches all the dimensions based on the test case input CSV and serialize it into a thrift message. it also stores the input and output in a Local Cache Map.
public static BilledEvent generateBillingInput(String[] csvRecord) throws Exception {
BilledEvent billedEvent = new BilledEvent();
RequestCommonDimensions requestCommonDimensions = new RequestCommonDimensions();
ImpressionCommonDimensions impressionCommonDimensions = new ImpressionCommonDimensions();
BidCommonReportingDimensions bidCommonReportingDimensions = new BidCommonReportingDimensions();
if (null != csvRecord[POSTSERVE_EVENT_TIME]) {
billedEvent.setEventArrivalTime(Long.parseLong(csvRecord[POSTSERVE_EVENT_TIME]));
}
if (null != csvRecord[POSTSERVE_REQUESTCOMMONDIMENSIONS_FLAG]) {
if(csvRecord[POSTSERVE_REQUESTCOMMONDIMENSIONS_FLAG].equals(TRUE)) {
billedEvent.setRequestCommonDimensions(ThriftEventParser.serializeEvent(requestCommonDimensions));
} else {
if (null != csvRecord[POSTSERVE_PUBLISHER_ID] && !csvRecord[POSTSERVE_PUBLISHER_ID].isEmpty()) {
requestCommonDimensions.setPublisherId(csvRecord[POSTSERVE_PUBLISHER_ID]);
}
if (null != csvRecord[POSTSERVE_DEVICE_TYPE] && !csvRecord[POSTSERVE_DEVICE_TYPE].isEmpty()) {
requestCommonDimensions.setDeviceType(Short.parseShort(csvRecord[POSTSERVE_DEVICE_TYPE]));
}
if (null != csvRecord[POSTSERVE_UMP_HOST_SLOT] && !csvRecord[POSTSERVE_UMP_HOST_SLOT].isEmpty()) {
requestCommonDimensions.setUmpHostSlot((byte) Integer.parseInt(csvRecord[POSTSERVE_UMP_HOST_SLOT]));
}
if (null != csvRecord[POSTSERVE_DC] && !csvRecord[POSTSERVE_DC].isEmpty()) {
requestCommonDimensions.setDc(DataCentre.findByValue(Integer.parseInt(csvRecord[POSTSERVE_DC])));
}
billedEvent.setRequestCommonDimensions(ThriftEventParser.serializeEvent(requestCommonDimensions));
}
}
It creates the event client based on the input configuration.
public static CompletableFuture
EventHubSinkConfig eventHubRegression = (new EventHubSinkUtil(configSubSet)).getSinkConfig(configSubSet);
String connectionString = EventHubSinkUtil.getConnectionString(eventHubRegression);
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
CompletableFuture
return eventHubClient;
}
It generates a Delta table for the regression run which a validator can query upon to get the output.
Thereafter, the validator validates on the basis of the query result from the Delta Lake and the local cache map which was generated while generating the test case.
On the validator result, it generates a success or a failure file.
public static void generateLogFile(boolean success, String CONFIG_PATH, String regressionRunUUID) {
Configuration config = ConfigurationUtil.getConfig(CONFIG_PATH);
StringBuilder regressionLogPath= new StringBuilder(config.getString(DatagenConstants.REGRESSION_LOG_PATH_CONFIG) + regressionRunUUID + "/");
StringBuilder regressionFileName=new StringBuilder();
if(success){
regressionFileName= regressionFileName.append(regressionLogPath).append(DatagenConstants.SUCCESS_FILE_NAME);
}
else{
regressionFileName=regressionFileName.append(regressionLogPath).append(DatagenConstants.FAILED_FILE_NAME);
}
DBUtilsHolder.dbutils().fs().put(regressionFileName.toString(),"",true);
log.info("Regression File Name {}", regressionFileName);
}
Releasing software isn’t just an art, it’s an engineering discipline too.
Once the code written by the developers are checked and passed, the software is essentially ready for deployment. We have Integrated the pipeline in Harness with Databricks to run the regression for the streaming job.
Generate the Regression Run ID
Fetch Regression Configuration and infra configuration
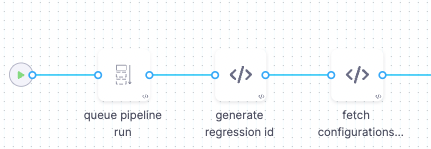
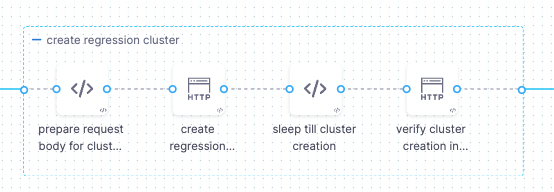
Prepare cluster creation request body.
Create a Databricks cluster.
Verify the cluster creation.
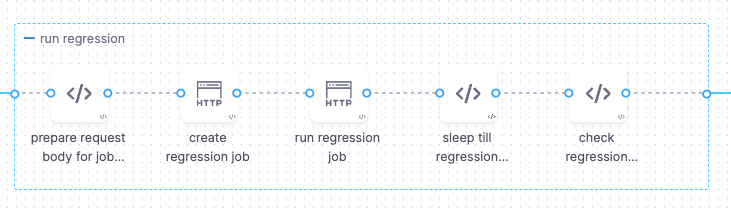
Prepare Regression Job Request Body
Create Regression Workflow Job on Databricks.
Check the Regression Status from the storage account for success/failure file for the Regression Run ID.
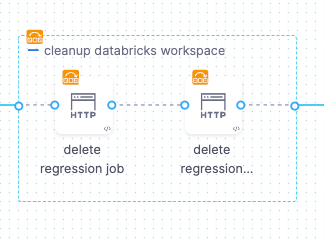
Delete regression job.
Delete regression cluster.
Databricks Cluster APIs |
||
|
Create a Cluster |
|
|
|
Verify a Cluster |
|
|
|
|
|
|
|
|||||
|
Create a Job |
|
|
|||
|
Run a Job |
|
|
|||
|
Delete Job |
|
|
|||
With the regression and CI/CD in place, we are able to validate and deploy the Streaming Job on Databricks in less than 5 minutes.
With regression in place, we will be able to validate the Streaming Job that doesn’t require the featured pilot for the Streaming Jobs to be in place.
With automation, developers can release new features and change more frequently, while teams will have better overall stability.
I hope after reading this article you may have a fair understanding of the streaming job and its regression and integration with Harness for the CI/CD pipeline.


Sign up with your email address to receive news and updates from InMobi Technology