

Apache Kafka is an open-source distributed event streaming platform which is widely used for high performance pipelines, streaming of events etc.
Kafka comes with some core capabilities of providing a high throughput which can go over 100s MB/s with 100Ks of messages/s at a very low latency (as low as 2ms).
There are multiple design decisions that have been taken while designing Kafka to make it such highly performant. Among them let’s consider two very important factors that contribute to it:
Sequential I/O
Zero Copy Principle
When data is stored on a storage device, it is organized into blocks, and each block has a unique address. When a computer reads or writes data, it uses the block addresses to locate the data. Random I/O refers to the process of reading or writing data from non-contiguous addresses, which can cause the disk head to jump around to different locations, resulting in slower read and write speeds.
On the other hand, sequential I/O refers to reading or writing data from contiguous blocks of memory. Because the disk head can move in a straight line, it is faster than random I/O. Additionally, modern hard drives and SSDs are optimized for sequential I/O and can read and write data much faster when it is laid out in a contiguous block.
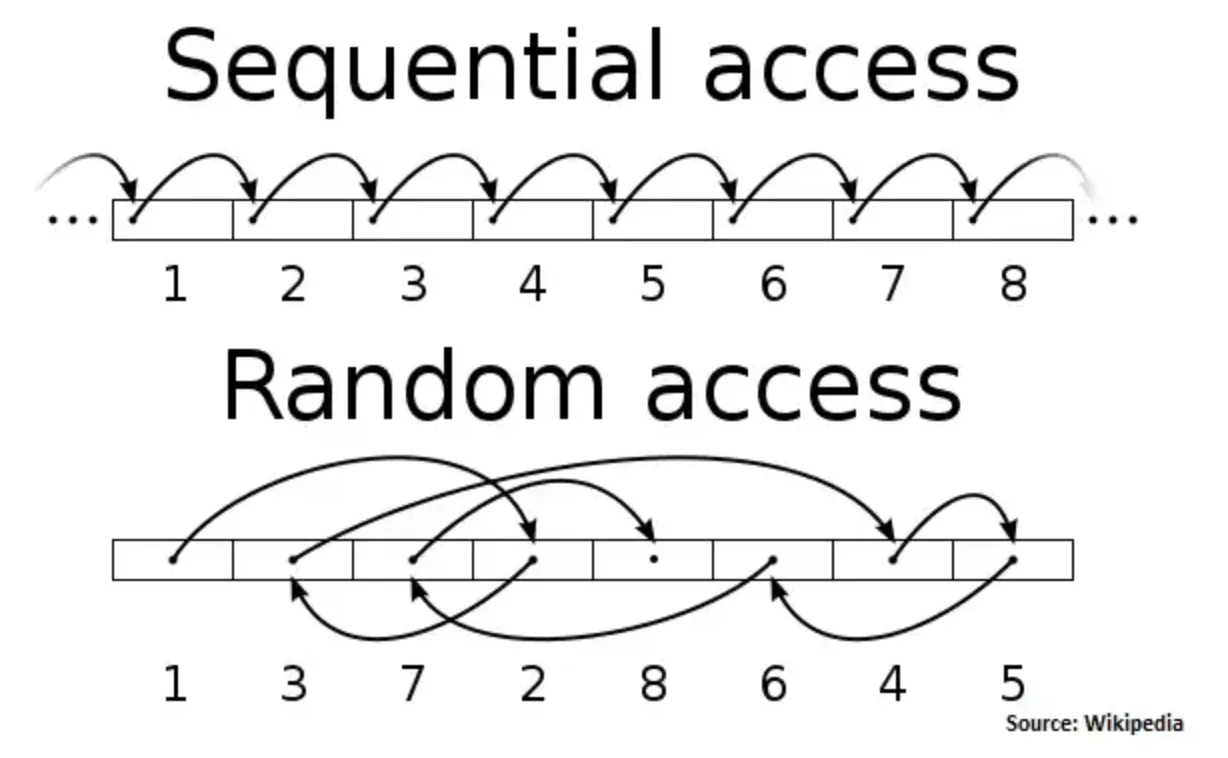
Sequential I/O is commonly used in systems that handle high throughput and large volumes of data, such as databases and data streaming platforms.
Kafka is designed to handle high throughput, low latency, and large volumes of data. One of the key factors that contributes to its performance is its use of sequential I/O. It uses sequential I/O to improve the performance of its log-based storage system.
Kafka stores all the data it ingests in a log-structured format, which means that new data is appended to the end of the log. This allows for very fast writes, since only the latest data needs to be appended, but it also means that older data needs to be periodically compacted to reclaim disk space.
Sequential I/O enables Kafka to take advantage of the performance benefits of writing and reading data in large, contiguous blocks rather than small, random blocks. By writing data in large blocks and reading data sequentially, Kafka can reduce the number of disks seeks and improve the overall throughput of the system.
In addition to this, Kafka also uses a technique called log compaction to clean up old data, which is also done in a sequential manner. It keeps the latest version of a message key, while discarding older versions, thus making use of the sequential IO when doing compaction.
By using sequential I/O, Kafka is able to achieve high write and read throughput while maintaining low latencies and high disk usage efficiency.

The zero-copy principle is a technique used in computer systems to minimize the number of times data is copied between different memory locations. This can significantly improve performance by reducing the amount of memory and CPU resources used.
When data needs to be transferred from one location to another, a traditional approach would be to copy the data from the source location to a temporary buffer, and then copy it again to the destination location. However, the zero-copy principle eliminates this intermediate step by allowing the data to be transferred directly from the source location to the destination location, without the need for an intermediate copy.
There are different ways to implement the zero-copy principle, but some common techniques include:
Memory mapping: This technique allows a process to access a file or other data source as if it were in its own memory space. This means that the process can read and write data to the file without the need to copy it to a separate buffer.
Direct memory access (DMA): This technique allows a device, such as a network card or disk controller, to transfer data directly to or from memory, without the need for the CPU to be involved in the transfer.
User-space libraries: Some user-space libraries like zero-copy libraries can help to implement zero-copy principles and eliminate the unnecessary data copies.
The zero-copy principle can bring many benefits to a system, such as reducing the amount of memory used, reducing CPU usage, and increasing throughput. It can also help to reduce latency and improve the overall performance of a system.
This allows for optimization of the most crucial operation in network transfer of persistent log chunks. Operating systems like Linux offer a highly efficient code path for transferring data from kernel context to a socket through the use of the sendfile system call.
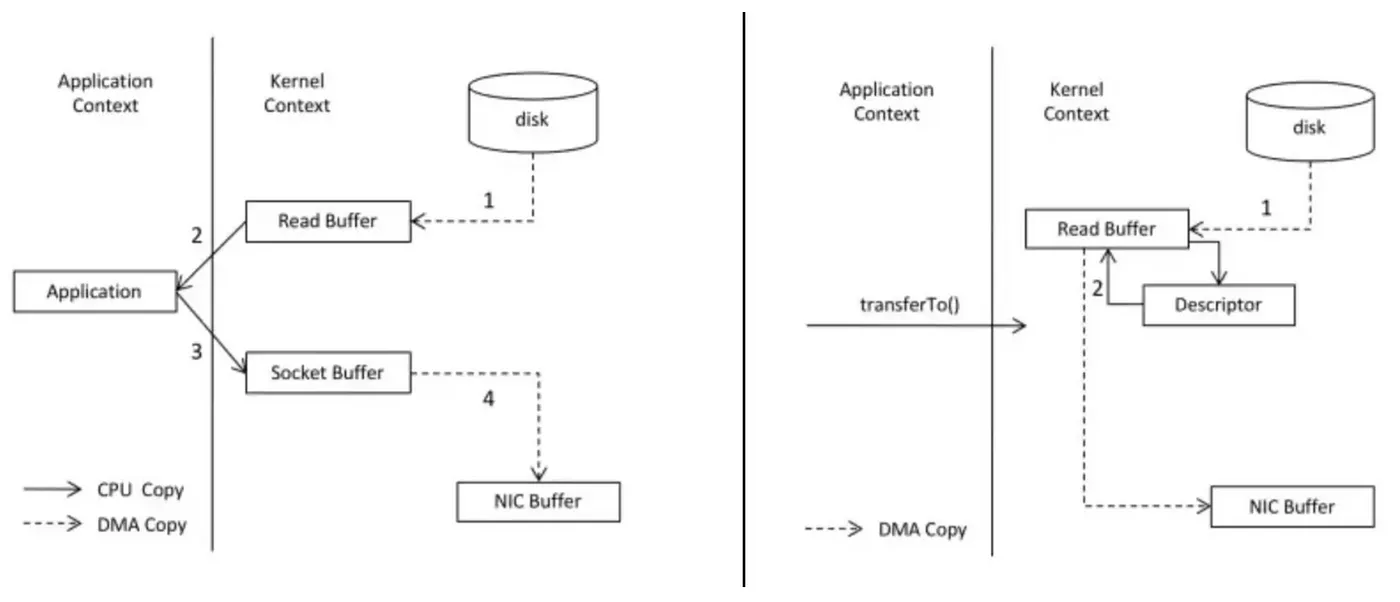
To grasp the significance of sendfile, it’s essential to understand the regular data path for transferring data from file to socket:
The operating system reads data from the disk into page cache (a component of the Linux kernel used to cache frequently accessed data from disk in memory to speed up data access) in kernel space.
The application reads the data from kernel space into a user-space buffer.
The application writes the data back into kernel space into a socket buffer.
The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network.
It’s clear that this process is not very efficient, as there are four copies and two system calls. However, using sendfile, this re-copying is avoided by allowing the OS to send the data from pagecache to the network directly. In this optimised path, only the final copy to the NIC buffer is needed.
Therefore, by using sendfile system call, modern Unix operating systems like Linux can transfer data from page cache to a socket efficiently, avoiding unnecessary copies and system calls.
Kafka uses the zero-copy principle to improve its performance by minimizing the number of copies of data that are made as messages are produced and consumed.
When a consumer reads a message from a Kafka topic, it can read the data directly from the log file, without the need to copy it into a separate buffer. This is achieved using a technique called direct memory access (DMA). DMA allows the consumer to read the data directly from the log file into the consumer’s memory buffer, without the need for an intermediate copy.
In summary, the zero-copy principle is a technique used in Kafka to minimize the number of copies of data that are created as messages are produced and consumed. By minimizing the amount of data that needs to be copied, Kafka improves performance and reduce the resources required to handle large volumes of data.


Sign up with your email address to receive news and updates from InMobi Technology