

Businesses in today's data-driven world generate huge data from various sources, including customer interactions, user behavior, and internal operations. To make the most of this data, companies need a platform that can store, process, and analyze data efficiently. One of the most critical components of a data platform is a data processing engine. The nature of data could be batched as well as real-time.
In this article, we will discuss the architecture of the data processing engine at InMobi’s Data Platform and how a single engine enabled multiple batch processing use cases across the board.
A Data Platform must perform various kinds of data processing tasks to fulfil its functional requirements. The following are some of the most common data processing tasks that a data platform may need to perform:
Data ingestion: Collecting data from various sources and bringing it into the data platform.
Data cleaning and normalization: Cleaning the data and ensuring that it's in a standard format for efficient processing.
Data integration: Combining data from various sources to create a single and unified view.
Data storage: Storing data in a format that's efficient and accessible for analysis.
Data processing: Performing operations like filtration, aggregation, and transformation on data to derive insights.
Data analysis and visualization: Analyzing data to identify patterns, trends, and anomalies that can inform business decisions and presenting it that’s easy to interpret and act upon.
Data security: Implementing measures like encryption to ensure the security of data.
Data governance: Implementing policies and procedures to ensure proper data management, including data quality, privacy, and compliance.
Data sharing: Making the data available to other systems or users in a controlled and secure manner.
A data processing engine performs operations on data like filtration, aggregation, and transformation. It's responsible for processing large volumes of data in real-time or batch processing modes. The data processing engine is a crucial component of a data platform because it allows businesses to transform raw data into valuable insights.
As mentioned above, there are too many functions that a Data Platform needs to serve. For all Batch data the easiest approach is to write a job that will provide the corresponding functionality. In this approach, there would be a single job for data standardization, another for ingestion, yet another job for compliance, and yet another job for data export and so on. This can be managed if there are just a few data sources, but as the number of data sources grow and each dataset comes in with a different schema, over a period of time this approach becomes infeasible.
The same was experienced at InMobi where the number of data sources and consequently the number of jobs grew so large that it became a humongous task to simply maintain so many jobs. The time to simply add a field required changes across multiple places and onboarding a new tenant was also time consuming. Further, with varying scale of incoming data, tuning so many independent Spark jobs was another nightmare. There weren’t relevant solutions readily available in the market that could solve exactly the same use case. Using any such solution would prove costly both in terms of time and money.
Given the problems above, there was a need to build a scalable and extensible data processing engine that could handle varying scale, support multiple use cases, and require minimal manual intervention for any new requirements.
Taking some inspiration from particle accelerators in Physics that speed up particles and project them in controlled directions, our data processing engine was born to accelerate data processing and send carefully crafted data to the required destinations. We named it Cyclotron.
Cyclotron is used for ETL operations, and its architecture is on similar lines. Let’s discuss in detail.
Since the aim of Cyclotron is to support multiple datasets, where each of them has different schemas and operations to be carried out on the data, the configuration management needs to be standardized. Overall, the configs are of the following two types:
Dataset Agnostic: There are some configurations that are required for the very functioning of the job that are independent of what dataset the job is running for. Examples of such a config could be a Spark config that needs to be set for all the datasets or a service URL that the job depends upon. These configs come from a config file for the job which is standard across datasets.
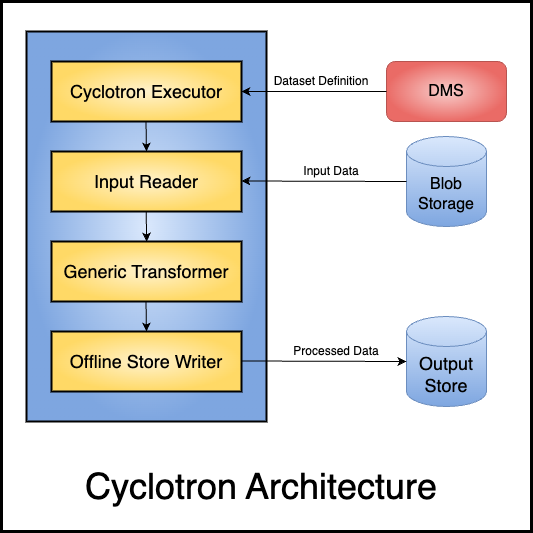
Dataset Specific: These are configs that vary across datasets. Examples include input data location, data format, set of transformations to be applied on the data, etc. Owing to a multitude of datasets to be handled, these configs are maintained in a separate service, named Dataset Management Service (DMS). Cyclotron gets all these configs from the DMS at execution time by making a REST call at the beginning of the job.
The abstractions used for Cyclotron are fairly simple and it is this simplicity that enables the support of multiple functionalities. The core abstractions are agnostic of the data processing framework, and it is the implementations that depends on specific details, like Spark. The main components are as follows:
InputReader:
This is the interface that is to be extended for reading any data. Different kinds of readers are supported, for example, a reader that reads input as a table, another one that reads data from an Azure Blob given its location etc. The specific reader to be used for a particular dataset operation is picked from dataset specific configs from the DMS. All field values required by the reader are configurable and also retrieved from DMS, such as the data format, location, compression format, source credentials etc. There are certain cases where we need to read data from multiple sources in a single job for performing enrichments, joins etc. Therefore, multiple input readers are supported, and each input source can have independent properties and schemas.
Transformer:
This is the interface that is to be extended for transforming data. It is this layer that is responsible for modifying the data. A few examples of transformations include changing the format of data, adding/removing columns, filtering out rows based on certain conditions for sanity, removing opted out users for compliance etc. The set of transformations to be applied is picked from DMS and changing the Transformation logic simply requires an update in the service. Actual application of the Transformation is done by Cyclotron, and it supports the following two kinds of Transformations:
Pre-defined Transformations:
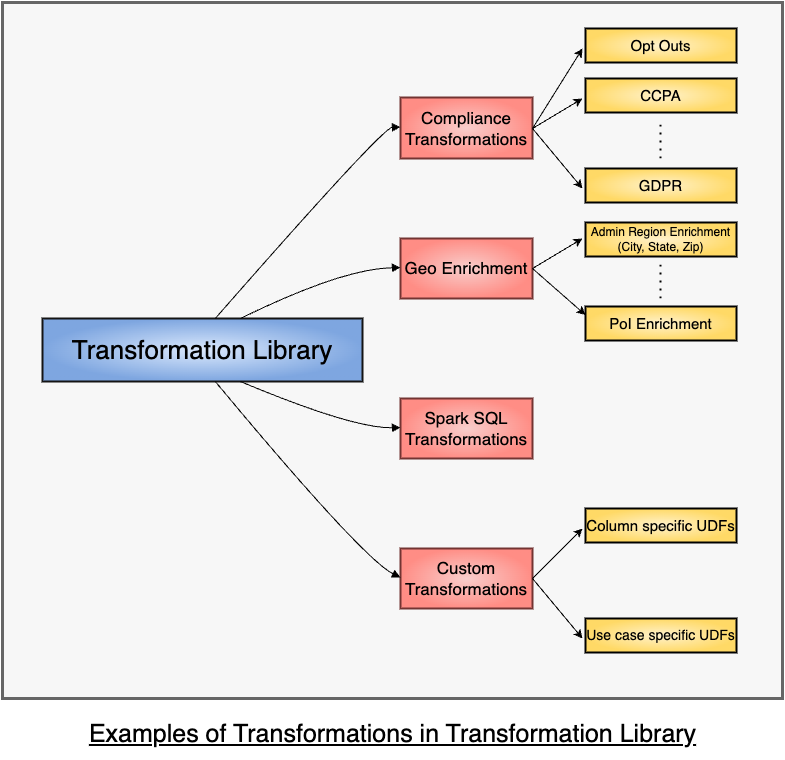
A Transformation Library is maintained with the set of all custom Transformations that may be required. These Transformations are dataset agnostic and can be reused across datasets. This Library contains definitions of various User Defined Functions (UDFs) to be applied on data, for example, UDFs to apply filters based on Compliance requirements. It also contains functionality to integrate with external services, such as Geo Service to enrich user data, for example, if the input data contains latitude and longitude for a device, the data can be enriched using an external lookup to add details such as city, zip code, points of interest etc. To apply any such custom Transformation, the fields on which the Transformation is to be applied are read from the configs and the schema of rest of the data doesn’t matter. This is what enables reusing Transformations across Datasets.
Spark SQL Transformations:
If there is a need to use an operation that is provided by Spark, the system supports SQL queries that are configurable and simply by adding a query, such custom processing can be done.
Note that no change is required in the code to change the applied Transformations, nor is any deployment required for the same.
OutputWriter:
This is the interface that is to be extended for writing data. As with Readers, different kinds of Writers are supported, for example, a writer that writes output to a table, another one that writes data to an Azure Blob given its location etc. The writer is also totally configurable and reads all the configs at runtime. These configs include functionality such as output location, format, write modes (like append, overwrite) etc. Writers can even divide the data into multiple parts and write to different locations. Data written by writers is maintained in a flat format as that massively improves the efficiency while writing and reading.
Executor:
The components discussed thus far perform single operations in line with the Single Responsibility principle. However, for them to work in an integrated way like a job, they need to be initialized and stitched together. There are also other things that a job requires as part of setup, such as establishing connections with a remote service like a Key Vault. This responsibility is accomplished by the Executor class.
When these simple, yet powerful constructs come together, they enable processing any kind of data seamlessly. Changing the schema of data is as simple as changing a query. Adding a new opinionated Reader or Writer is as simple as extending an interface. It is a common scenario that multiple jobs read from/write to the same store. In such a case, we don’t need to repeat any code across jobs as the same implementations can be used just by specifying a config.
Adding a new job with a different business functionality can be done by writing a new Executor that just stitches various Readers, Transformers, and Writers. Having a separate Executor this way enables minimal turnaround time in implementing any new feature.
Cyclotron, that was written originally as a job to only ingest data soon turned into the Data Processing Engine for maximum use cases such as Data Preprocessing, Rollups, Compliance, Data integration to a Data Lake etc. Further, the abstractions have proved powerful enough to be further used for jobs responsible for Encryption/Decryption, Data Export, Analytics, Data Merger etc. If you observe, this includes every single data processing functionality listed above that is required in a Data Platform.
From an engineer’s perspective, understanding the whole system has become much easier because understanding one single job gives complete insight into the technical structure of the whole platform and only the business logic varies.
Pipeline deployment is automated and a new Dataset for processing is onboarded by specifying its details in DMS. These details are picked by a Provisioning Pipeline that deploys the resources. As a result, setting up the whole pipeline is seamless, enabling us to quickly scale the platform to onboard multiple data partners.
Similarly even the expected scale of data can be specified in DMS. Based on the scale specified, Provisioning Pipeline allocates resources to the job and sets Spark configs. This enables handling of variation in scale seamlessly. In case the volume of any dataset increases manifold, just changing the config provisions extra resources for future runs of the job and no code changes are required in this process.
Metrics are critical for monitoring the health of any system. Cyclotron emits metrics automatically whenever a Transformation or a query is applied on data which enables tracking any abnormal variation in data volumes. Not only does it evaluate metrics at the beginning and culmination of a job, but after every single stage as a result of which the behavior of every single Transformation can be tracked individually.
Overall, Cyclotron has resulted in overall standardization of Spark jobs and a lean stack that provides many benefits for business, including reduced costs, improved performance, increased security, easier maintenance, and faster development. By keeping the technology stack simple and streamlined, the business can focus on delivering value to customers without being bogged down by complexity.


Sign up with your email address to receive news and updates from InMobi Technology