
For high-performance and large-scale analytics, using approximate algorithms to get cardinality estimates across different dimensions of data is a common technique.
One of the ways is to use Spark SQL’s approx_distinct_count which returns the estimated count of distinct values in a group.
Pre-aggregation is usually performed to speed up interactive analytics and Spark Alchemy provides functionalities to aggregate, reaggregate, and present the cardinality estimates.
This article discusses why and how we enabled Spark Alchemy’s functionalities as Native Spark functions in Databricks.
HyperLogLog is an algorithm that is extensively used in our Audience Intelligence team to enable Pre Sales and Account Managers to quickly estimate the effectiveness of a custom audience/segment during pre-campaign analysis.
A Private Market Place (PMP) is a transaction type in programmatic ad buying where exchanges curate custom audiences to suit an advertiser’s needs as part of a deal.
For a PMP, it's useful to know the effectiveness of the combination of segments in the deal before the standard (prebuilt) segments are packaged.
Effectiveness is measured in terms of metrics like segment reach (device count), number of unique users (UU), number of households (HH), number of screen extensions, number of hashed email addresses (HEMs), and the number of MAID (Mobile Ad ID) matches with active users on Exchange.
For example, one can visit our platform to know the estimated reach of ‘music lovers in California.’
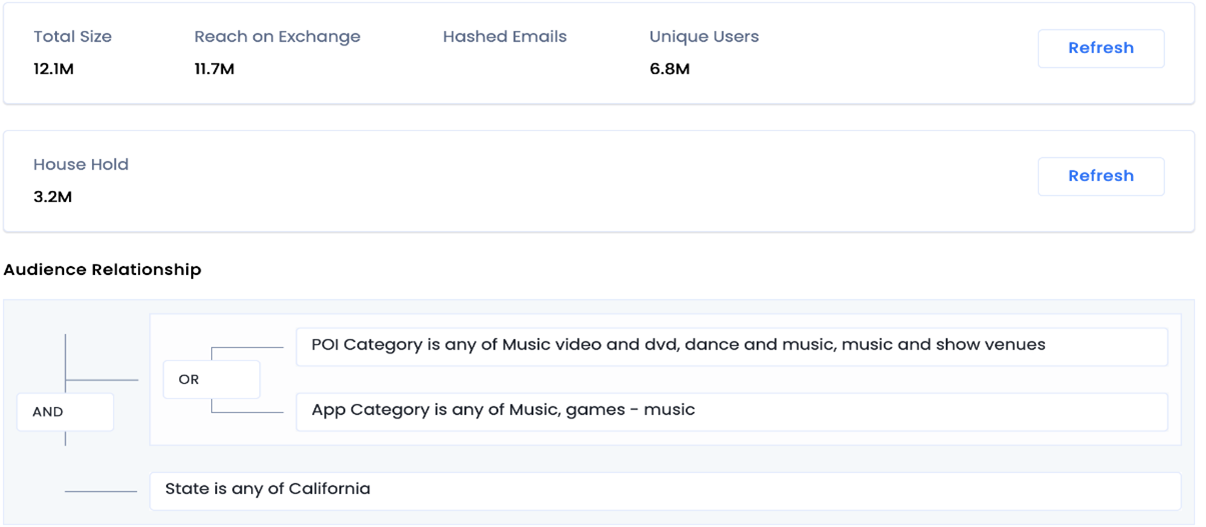
OR to know the estimated reach of a combination of two segments - ‘Females in the US AND those who are cat lovers.'
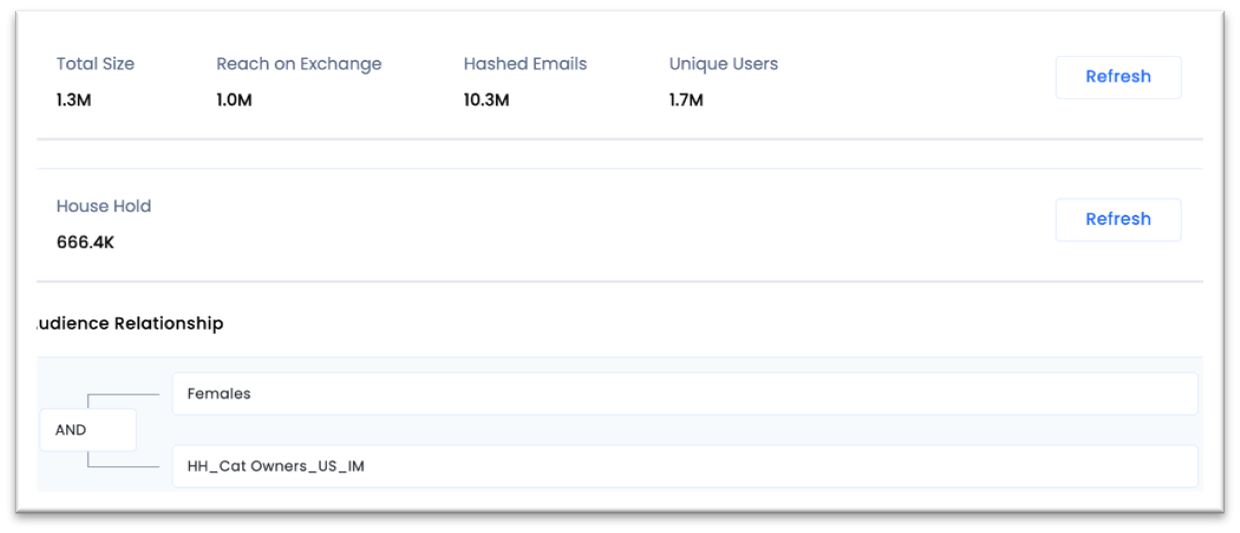
AND the results are available within seconds.
Adding HyperLogLog (HLL) functionality in a Spark Context is straightforward using the Spark Alchemy library. This library, written in Scala, provides HLL functions that seamlessly integrate with Spark-supported languages like Python and Spark SQL, offering maximum performance and flexibility.
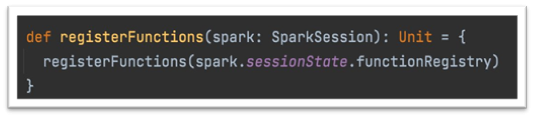
Like user-defined Functions (UDFs), one needs to register these functions to an existing Spark Session using the Scala interface provided by the library.

Internally, this is how the HLL functions are registered to the session’s function registry.
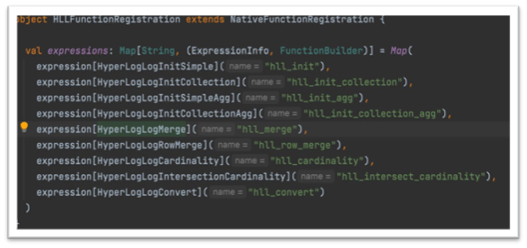
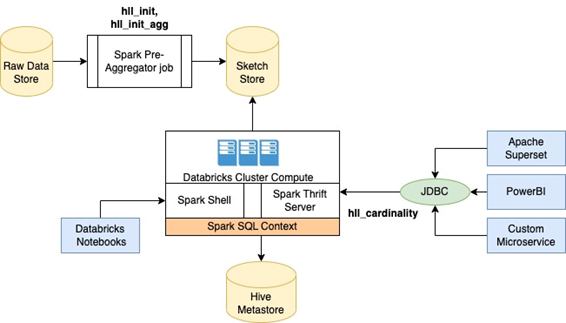
Aggregate and reaggregate HLL functions like hll_init and hll_init_agg are used in our scheduled Spark jobs to generate userId sketches for multiple combinations of feature dimensions (this is what we call our sketch store). But querying functions like hll_cardinality and hll_intersect_cardinality had to be used more interactively through Apache Superset, PowerBilt or our own UI.
Superset and other non-spark microservices require the ability to execute HLL queries through JDBC connectors. These queries are typically directed towards the Spark Thrift Server which is a service that allows JDBC and ODBC clients to run Spark SQL queries.
Product and Business teams access our sketch store through Databricks Notebooks. This required them to include the function registration step in their Standard Operating Procedure before running any HLL queries. Unfortunately, this manual step is often missed or forgotten, resulting in frustration when a HLL query fails due to the error message 'function not found'.

We tried enabling session sharing in Databricks. In Databricks, for security reasons the Spark session isolation is enabled by default. This means that the notebooks attached to the same Databricks cluster are in different Spark sessions with isolated runtime configuration. Restarting the cluster spark.databricks.session.share to ‘True’ disables session isolation and allows data sharing across different notebooks. By using this, we could register the HLL functions through one notebook and then any other notebook created by product or business teams in the same workspace will have access to these functions. But the downside to it was that cluster restarts still needed this manual registration step, and it did not solve the second problem of executing HLL queries from a JDBC context.
Databricks REST API offers programmatic way to execute a Python/Scala/SQL code on the cluster. By using this, we could create an equivalent of a Notebook’s execution context – at first register the Scala function, and then in the same context execute the HLL query. Although, this could work for the microservice API use-case, but for the Notebook use-case we still needed a solution as session sharing is not recommended.
We could have created a permanent function by implementing HLL functions as Hive UDFs (extending org.apache.hadoop.hive.ql.exec.UDF), but Spark Alchemy had implemented HLL as native Spark functions, and we still needed a way to execute HLL queries from a JDBC context.
Spark native functions are executable nodes in a Catalyst Expression tree that can take one or more inputs and evaluate them.
An expression can be unary/binary/leaf expression depending on the number of children in the tree. All SQL functions are implemented as native functions. For example, the SQL function upper is implemented as follows:

Spark Native Functions are known to be more performant than UDFs because they work on Spark’s internal representation of rows which can avoid serialization/deserialization to/from normal datatypes and can take advantage of predicate push down.
From Spark version 2.2.0, Spark provides Extension hooks through which custom parsers, analyzer rules, optimizer rules, planner strategies and even custom functions can be injected into the Catalyst’s query execution plan.
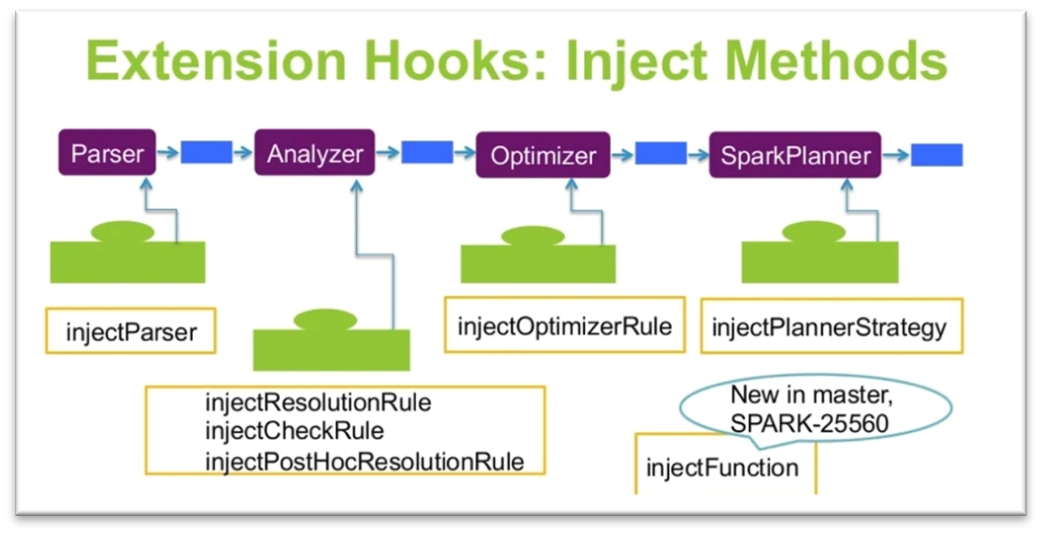
Define the custom Expression class. In our case, the Expression class was already available in the Spark Alchemy library.


Define an Extension class by extending the SparkSessionExtensions class and overriding the injectFunction method with the required FunctionDescription.
This is a new class we added to the Spark Alchemy library.
FunctionDescription is a combination of 3 entities.
FunctionIdentifier → stands for name of the function, as would be used from Spark SQL
ExpressionInfo → reference to the Expression class created in Step 1
FunctionBuilder → sequence of expressions
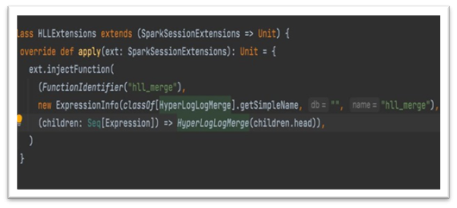
Make the Extension class available to the FunctionRegistry.
One way to add this extension to the current Spark Context is to pass the class in withExtensions while building SparkSession

Another way to inject it permanently on a Spark cluster is to start the cluster by passing the Extension class to the spark config, spark.sql.extensions.
This is a static Spark SQL configuration as it is immutable and available across multiple sessions.
The SparkSessionExtension keeps track of the injected classes and during session catalog creation, the injected functions are registered in the FunctionRegistry.
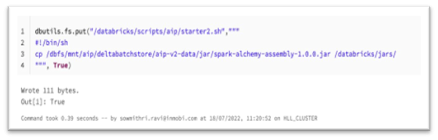
In our Databricks setup, we have made the HLL Extensions (Spark Alchemy library) available in the cluster’s library path through an init script and included the spark.sql.extensions configuration in the cluster config.
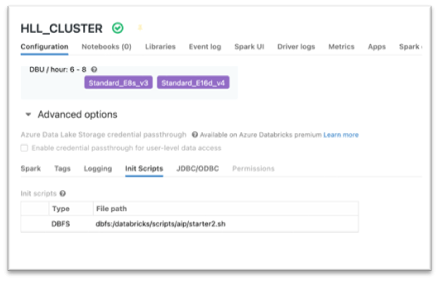
The init script copies the extended Spark Alchemy jar to /data bricks/jars/ location.
Adding the jar in the 'Libraries' section will not work as the extension classes need to be available before the Spark driver or worker JVM starts.
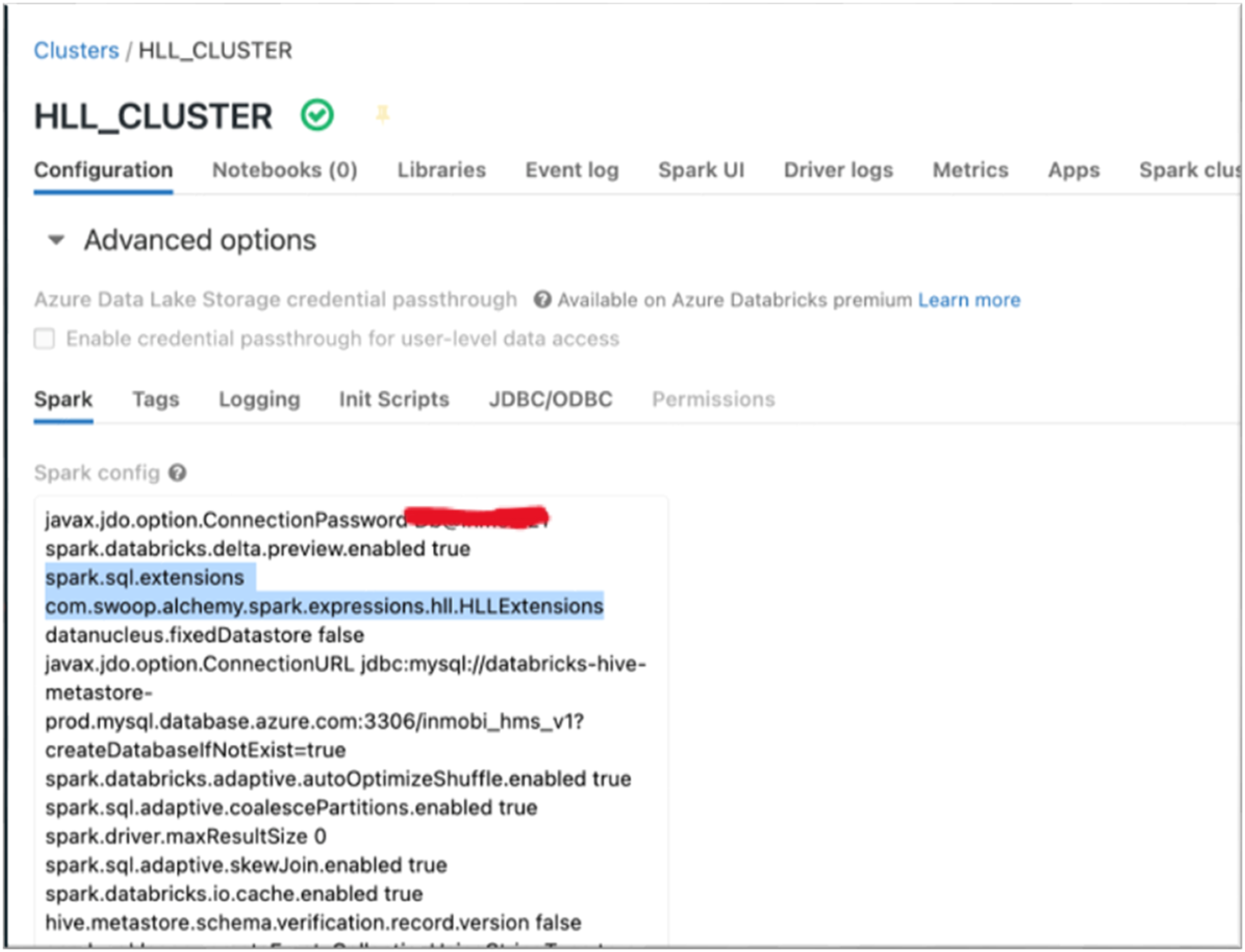
By augmenting the Spark Alchemy library with an HLLExtension class and adding it to the cluster's Spark config we could enable HLL capabilities as native Spark functions in our cluster. So, any notebook, pipeline or application using this cluster can fire HLL queries, just like any other Spark SQL query.


Sign up with your email address to receive news and updates from InMobi Technology