

At InMobi, we place utmost importance on safeguarding the privacy of user data, making it a paramount concern. As a responsible data company, we are committed to adhering to the highest standards of data protection and compliance with relevant privacy regulations, including the California Consumer Privacy Act (CCPA) and the General Data Protection Regulation (GDPR).
To effectively address these concerns, we have adopted the Databricks Lake House platform, which enables us to build scalable, robust, and resilient data platforms that empower us to extract maximum value from our data and better serve our customers while ensuring the utmost security and privacy for our users.
As the volume and complexity of data continue to grow at an exponential rate, the need for stringent data management and governance practices has become even more critical. To this end, we are committed to complying with all privacy regulations that require us to potentially delete all personal information about a consumer upon request.
With the Databricks data-lake architecture and Delta Lake, we have implemented a range of measures to ensure that we meet these requirements. By utilizing the latest data management and governance technologies, we can effectively protect user data privacy while maintaining the integrity and availability of our data assets.
Our commitment to privacy compliance is an ongoing journey as we continue to invest in best practices and innovative solutions to meet evolving regulatory requirements and the needs of our customers.
The following are the few data subject rights in GDPR:
Right to Access [RTA]
Right to Opt-out [RTO]
Right to be Forgotten [RTF]
As we move ahead, we will focus on the challenges with respect to the data subject “Right to be Forgotten” at the data lake:
What is the biggest challenge in fulfilling the "right to be forgotten" requirement when dealing with large volumes of data, specifically in regard to erasing the data from a data lake?
What are the possible ways to delete data at a record level when working with large file sizes (typically recommended file sizes of around 250 MB) in analytics systems that utilize processing frameworks such as Spark or MapReduce?
Understanding the Apache Spark supported file formats:
Apache Spark offers support for several file formats including Parquet, JSON, CSV, TXT, Hudi, and Delta. These formats can be categorized into two groups based on their transactional properties:
Transactions File Formats: Hudi, Delta
Non-Transactional File Formats: Parquet, JSON, CSV, TXT
Parquet files are immutable, which means that they don’t allow you to add or delete rows. If you want to delete rows from a Parquet file, read the data into memory, filter out the unwanted rows, and create a new Parquet file.
Size of Data: 25 TB
Job Time: 30 hours
Cluster Size: 25 nodes
Instance Type (Databricks): Standard_E16as_V4 [128 GB Memory, 16 Cores]
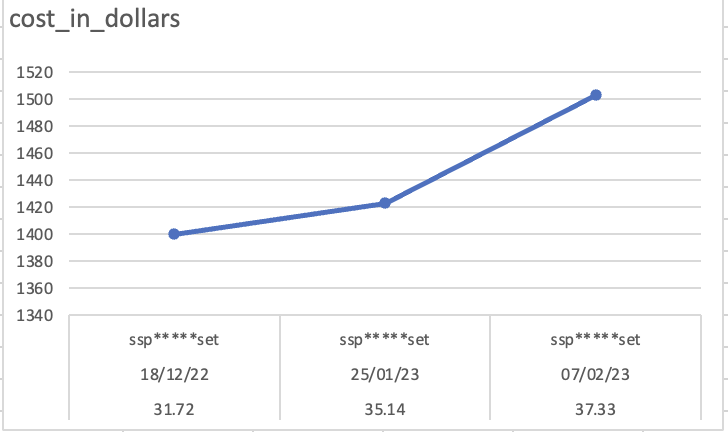
The cost of the jobs has exhibited a persistent and noteworthy upward trend, coinciding with a significant surge in the volume of requests that we have been receiving from publishers on a monthly basis clearly indicating the lack of scalability. This pattern of escalation underscores the seriousness of the situation and suggests that proactive measures may be required to address this issue in a timely and effective manner.
Given the multitude of jobs that we currently have in operation, each running on distinct datasets, it’s concerning that the average total cost incurred to fulfill the "right to forget" task has been hovering within a range of $8,000 to $11,000 per month. This figure represents a significant expenditure for the company, and its consistent occurrence highlights the gravity of the situation. It is imperative that we take swift and strategic action to address this issue and identify potential cost-saving measures without compromising the quality and efficacy of our services.
NOTE: It’s observed that non-transactional file formats, specifically Parquet, ORC, etc., present a limitation in supporting DML actions such as DELETE. Due to this limitation, complete table scans are required, and backups must be maintained in case of partial job failure. To address this issue, we transferred all data from the non-transactional Parquet format to a transactional format, specifically ‘Delta’. This move will eliminate the aforementioned limitations and streamline the process of performing DML actions on the data.
We use Azure Databricks for our analytics platform.
The Delta data format in Spark offers two distinct approaches or commands for deleting data. In compliance with the "Right to be Forgotten" regulation, it is imperative to delete any personal information associated with a particular consumer based on specific key columns such as user_device_id or email_id.
The following are the two approaches that can be leveraged to delete data in Delta tables:
Using DELETE FROM query, for example DELETE FROM table_name [table_alias] [WHERE predicate].
Delta Lake performs a DELETE on a table in two steps:
The first scan is to identify any data files that contain rows matching the predicate condition.
The second scan reads the matching data files into memory, at which point Delta Lake deletes the rows in question before writing out the newly cleaned data to disk.
Using MERGE INTO, query for example MERGE INTO target_table t USING source_table s ON t.key = s.key WHEN MATCHED THEN DELETE SET new_value = s.new_value.
Delta Lake performs a MERGE on a table in two steps:
Perform an inner join between the target table and source table to select all files that have matches.
Perform an outer join between the selected files in the target and source tables and write out the updated/deleted inserted data.
NOTE: The main way that this differs from a DELETE under the hood is that Delta Lake uses joins to complete a MERGE. This fact allows us to utilize some unique strategies when seeking to improve performance.
To validate the performance and scenarios for deleting data from Delta Lake, the following cases were considered to find the optimal way of deleting the data:
InputTable1 (on which the RTF is to be applied):
Number of rows: 100K distinct rows.
Key Column: ID as string
InputTable2 (on which the RTF is to be applied):
Number of rows: 10M distinct rows.
Key Column: ID as string
LookUpTableV1 (list of IDs that need to be deleted):
Number of IDs overlapped with InputTable: 0
LookUpTableV2 (list of IDs that need to be deleted):
Number of IDs overlapped with InputTable: 10,00,000 distinct rows.
NOTE: Input Table has been Z-ordered over the Key Column: ID
Case 1: Considering InputTable1 and LookUpTableV1:
Using a DELETE query on delta-lake for which no lookup exists:
%sql
DELETE FROM table_dltupd_v1 WHERE user_id IN (SELECT `uuid` FROM table_lookup_not_matched)
It took around 0.51 seconds to run.
Using a MERGE query on delta-lake for which no lookup exists:
It took around 3 seconds to run
Case 2: Considering InputTable2 and LookUpTableV2 :
Using a DELETE query on delta-lake for which a lookup exists:
%sql
DELETE FROM table_dltupd_new_v1 WHERE user_id IN (SELECT user_id FROM lookUpTablev2_new)
It took around 1.23 minutes to run.
Using a MERGE query on delta-lake for which a lookup exists:
%scala
import io.delta.tables.DeltaTable
import org.apache.spark.sql.functions.broadcast
DeltaTable.forPath(spark, "wasbs://offlinestore@epsilonpreprodstorage.blob.core.windows.net/table_dltupd_new_v2")
.as("base")
.merge(
broadcast(spark.table("lookUpTablev2_new").select("user_id").as(
"updates")),
"base.user_id = updates.user_id")
.whenMatched()
.delete()
.execute()
It took around 0.51 seconds to run.
NOTE: The auto-broadcast has been turned off for the analysis.
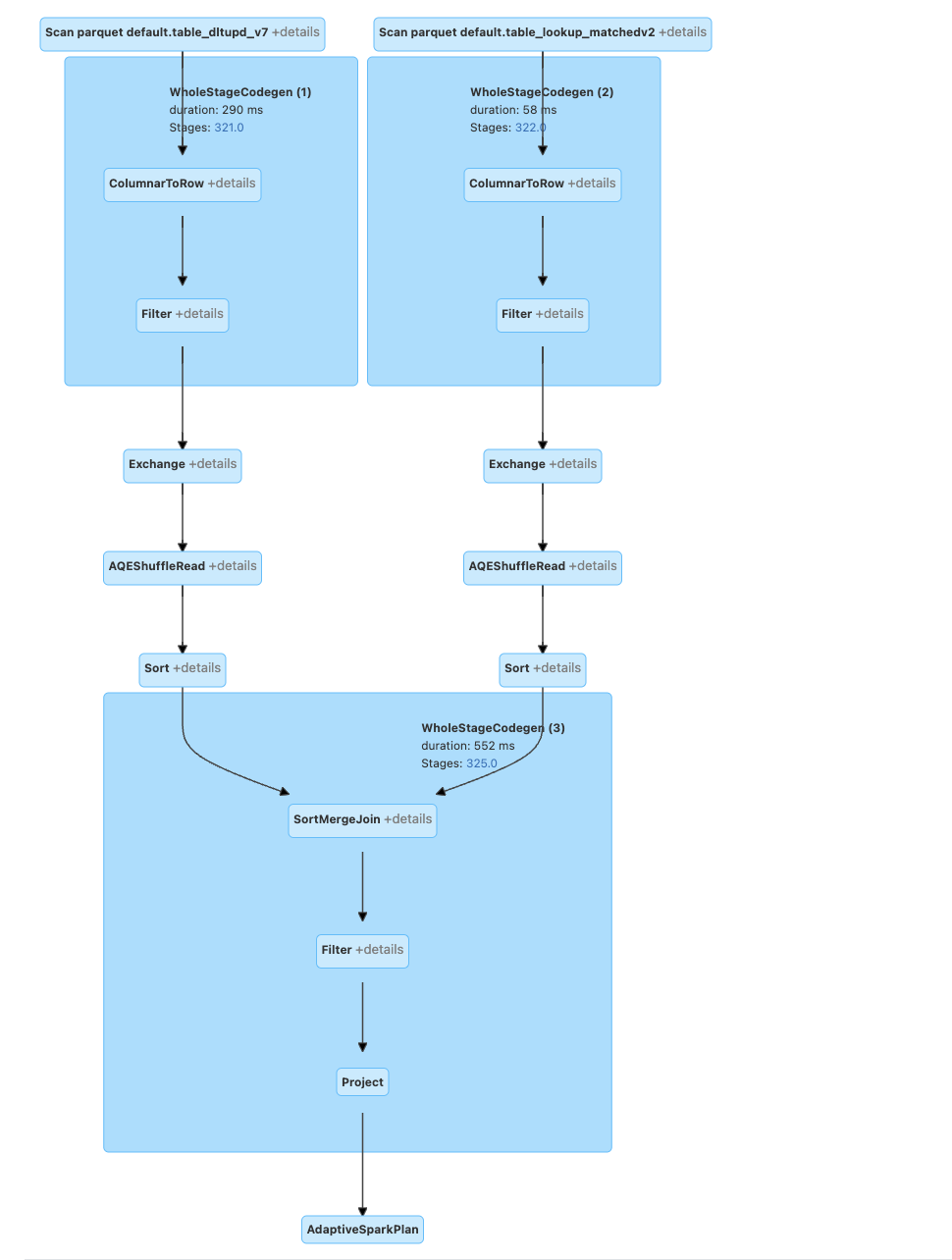
DELETE Query: As we can see, it performs a sort-merge join, and the delete query does not support BROADCAST hints. Hence, if we want to enforce broadcast join over delete externally is not feasible.
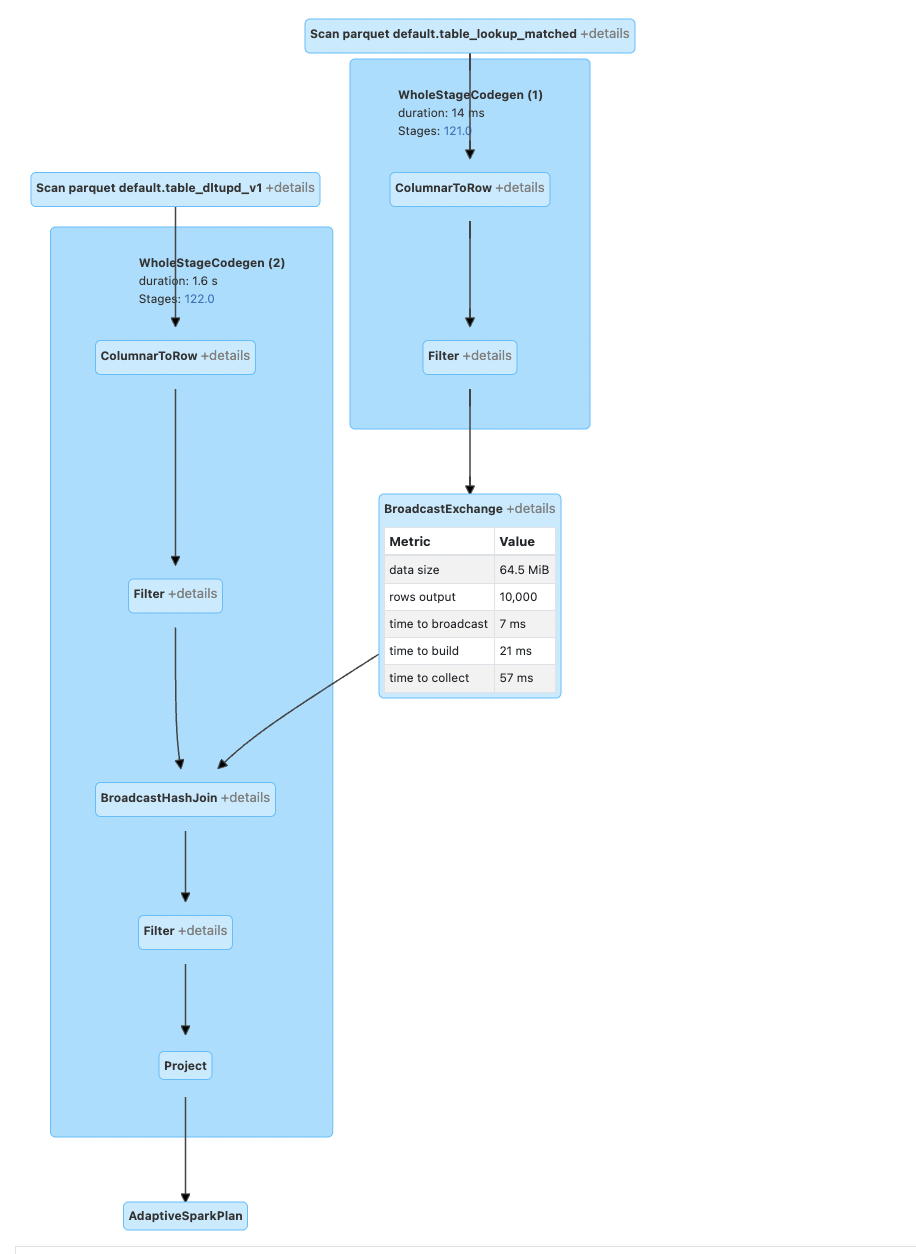
MERGE Query: To gain advantage of doing lookups using broadcast joins for deleting data, we can leverage the merge query construct supported by Delta-Lake. As shown below, query plan for the same.
If the match rate of ids in the Actual vs. Lookup table is lower, use the DELETE query to delete the data.
If the match rate of ids in the Actual vs. Lookup table is higher and the lookup table is huge, use the MERGE strategy to delete the data.
NOTE: In the Databricks runtime version 12.1 or more, there is a possibility of doing a soft delete. Deletion vectors indicate changes to rows as soft deletions that logically modify existing Parquet data files in the Delta Lake table.
These changes are applied physically when data files are rewritten, as triggered by one of the following events:
An OPTIMIZE command is run on the table.
Auto-compaction triggers a rewrite of a data file with a deletion vector.
REORG TABLE ... APPLY (PURGE) is run against the table.
Previously, each month's operations required some form of manual execution, consuming valuable bandwidth in each sprint solely for running RTF. However, with the migration to the delta architecture and the implementation of the delete query functionality, we have successfully automated the deletion process for each month. This automation has allowed us to allocate our resources more effectively and utilize the saved time for other essential tasks and projects. Initially, a single job took approximately 39 hours to complete. However, with the new RTF framework in place, the time required for execution has been reduced to just 15 hours, resulting in significant Time Savings.
In addition to the time savings achieved, the adoption of the new RTF framework has also resulted in significantly reduced costs representing a substantial decrease in our operational expenditures.
Databricks Low Shuffle Merge provides better performance by processing unmodified rows in a separate, more streamlined processing mode, instead of processing them together with the modified rows. As a result, the amount of shuffled data is reduced significantly, leading to improved performance. Low shuffle merge tries to preserve the existing data layout of the unmodified records, including Z-order optimization. Previously, achieving z ordering for data required runs of optimization jobs on the entire data post RTF pipeline on each dataset, consuming significant resources and time. However, our new system eliminates the need for this post-RTF by utilizing low shuffle merge. This ensures that data is written in an already z-ordered manner, eliminating the need for optimization jobs.


Sign up with your email address to receive news and updates from InMobi Technology