

The rapid advancement of the internet has led to the explosive growth of data. Around 80 to 90 percent of the data generated and collected by organizations is unstructured, and its volumes are rapidly expanding -significantly outpacing the growth rate of structured databases. Unstructured data stores encompass a vast amount of valuable information that can be utilized to inform business decisions.
Image Credit: Domo
Picture yourself adrift in the boundless realm of the internet, endeavoring to find a valuable piece of information concealed amidst the multitude of websites scattered across the digital landscape. In the past, conventional keyword-based search engines were the primary means of accessing such information. These search engines would scour through a vast collection of documents and present results containing the specified keywords from your search query. However, it is important to explore the inherent constraints of this approach, which we will discuss in the following section.
Word ambiguity and synonyms — Some words are ambiguous like ‘Jaguar’, which could mean an automobile company, an animal, American professional football team or something completely different.
Biased ranking — Some web pages use excessive keywords to boost up SEO on their domain, which might prove irrelevant to a user searching for something else.
Language — In addition to the challenges presented so far, language support adds another layer of complexity.
Semantic search in a vector database involves using vector representations of data to perform search and retrieval based on the semantic meaning of the content rather than just keywords or exact matches. Vector search powers semantic or similarity search. Since the meaning and context is captured in the embedding, vector search finds what users mean, without requiring an exact keyword match. It works with textual data (documents), images, and audio.
So now we will try to understand these steps in detail by writing some code.
Dealing with text data is problematic, since our computers, scripts and machine learning models can’t read and understand text in any human sense. Therefore, we use a technique called ‘embedding’ to represent data in the form of numerical vectors in higher dimensional space. In the context of semantic search, embeddings are generated through deep learning models, such as word embeddings (for example, Word2Vec, GloVe) for natural language data or image embeddings for visual data.
Let’s see how we can get embedding using OpenAIEmbeddings.
import openai
response = openai.Embedding.create(
input="My name is Adriraj",
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
embeddings[:5]
# Response (1536 parameters)
# [-0.00930609367787838,
# 0.0033837351948022842,
# -0.013574400916695595,
# -0.009516549296677113,
# -0.00981250312179327 ...]
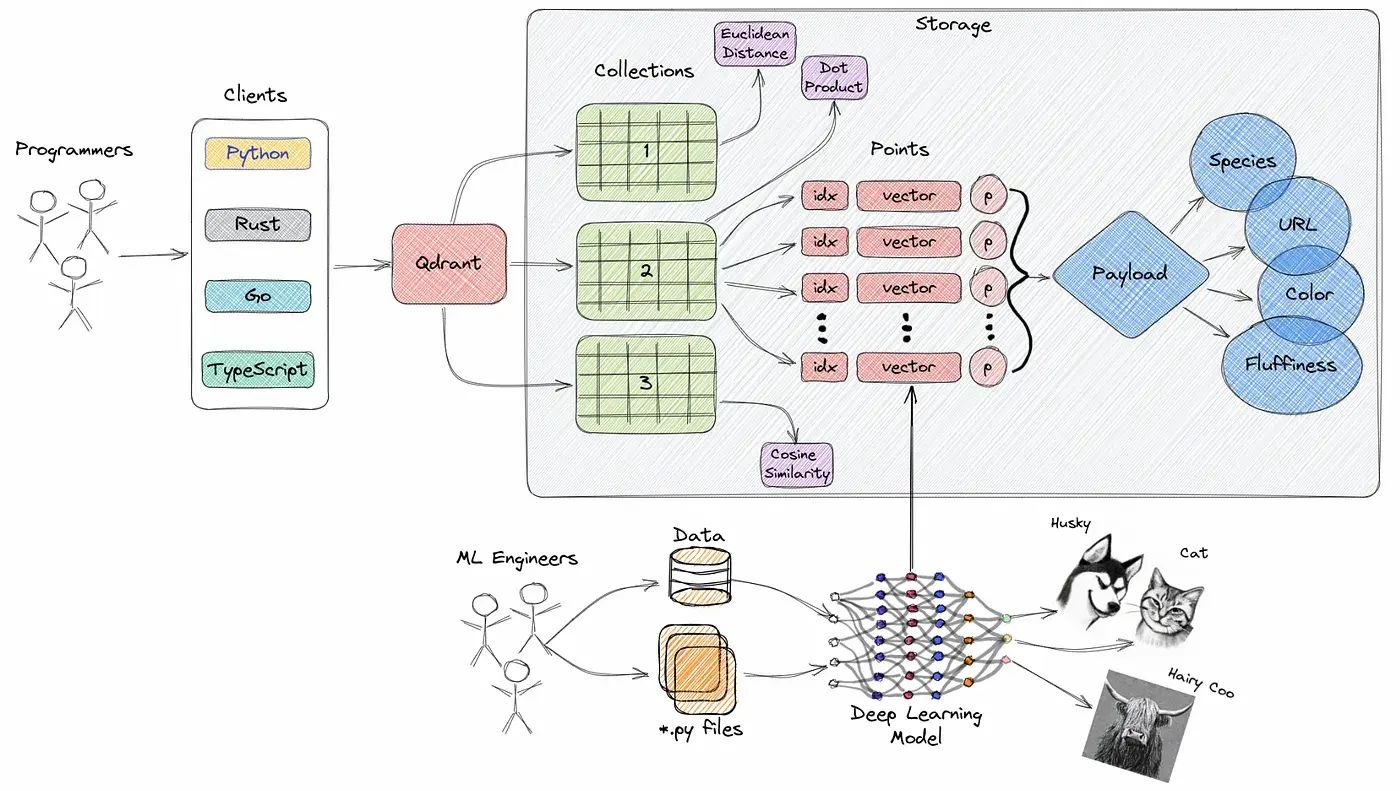
Vector database is a type of database designed to store and query high-dimensional vectors efficiently. Here we are using Qdrant — a vector similarity search engine that provides a production-ready service with a convenient API to store, search, and manage points (i.e., vectors) with an additional payload. One of the main reasons behind choosing Qdrant is because it supports asynchronous operations.
Vector databases are optimized for storing and querying these high-dimensional vectors efficiently, and they often using specialized data structures and indexing techniques such as Hierarchical Navigable Small World (HNSW) — which is used to implement Approximate Nearest Neighbors — and Product Quantization, among others. These databases enable fast similarity and semantic search while allowing users to find vectors that are the closest to a given query vector based on some distance metrics like Euclidean Distance, Cosine Similarity, and Dot Product, and these three are fully supported Qdrannt.
# Create Qdrant Client
from qdrant_client import QdrantClient
from qdrant_client.http import models
client = QdrantClient(
url=QDRANT_HOST_URL,
api_key=QDRANT_API_KEY,
)
client.recreate_collection(
collection_name="my-collection",
vectors_config=models.VectorParams(
size=1536,
distance=models.Distance.COSINE
)
)
To understand more about HNSW, let us first look at data structures being used internally — skip lists and navigable small worlds.
Skip list is a probabilistic data structure that allows inserting and searching elements within a sorted list for O(logn) on average. A skip list is constructed by several layers of linked lists. The lowest layer has the original linked list with all the elements in it. When moving to higher levels, the number of skipped elements increases, thus decreasing the number of connections.

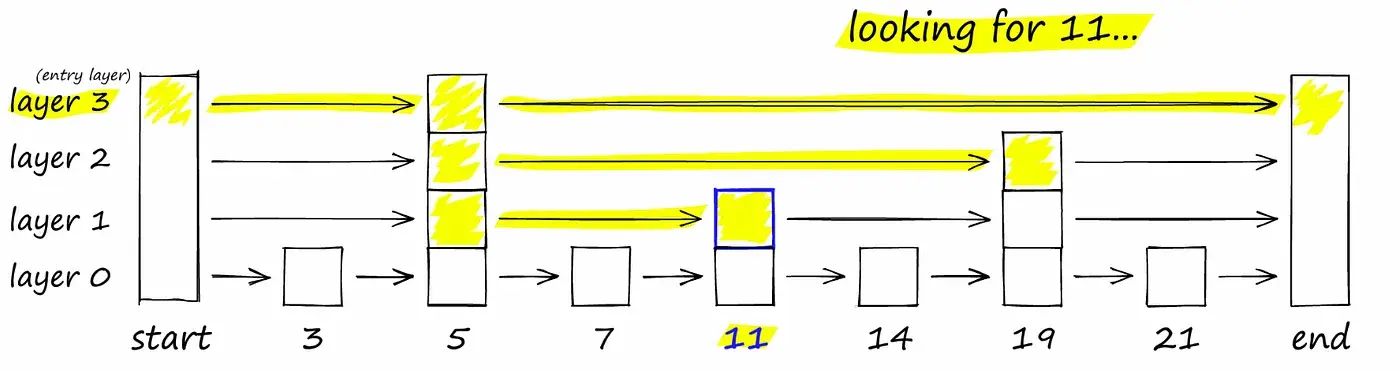
Searching starts in the sparsest subsequence until two consecutive elements have been found, one smaller and one larger than or equal to the element searched for. Via the linked hierarchy, these two elements link to elements of the next sparsest subsequence, where searching is continued until finally searching in the full sequence.
Navigable small world is a graph data structure which uses greedy routing approach for search operations. This approach starts with low-degree vertices and ends with high-degree vertices. Since low-degree vertices have very few connections, the algorithm can rapidly move between them to efficiently navigate to the region where the nearest neighbor is likely to be located. Then the algorithm gradually zooms in and switches to high-degree vertices to find the nearest neighbor among the vertices in that region.
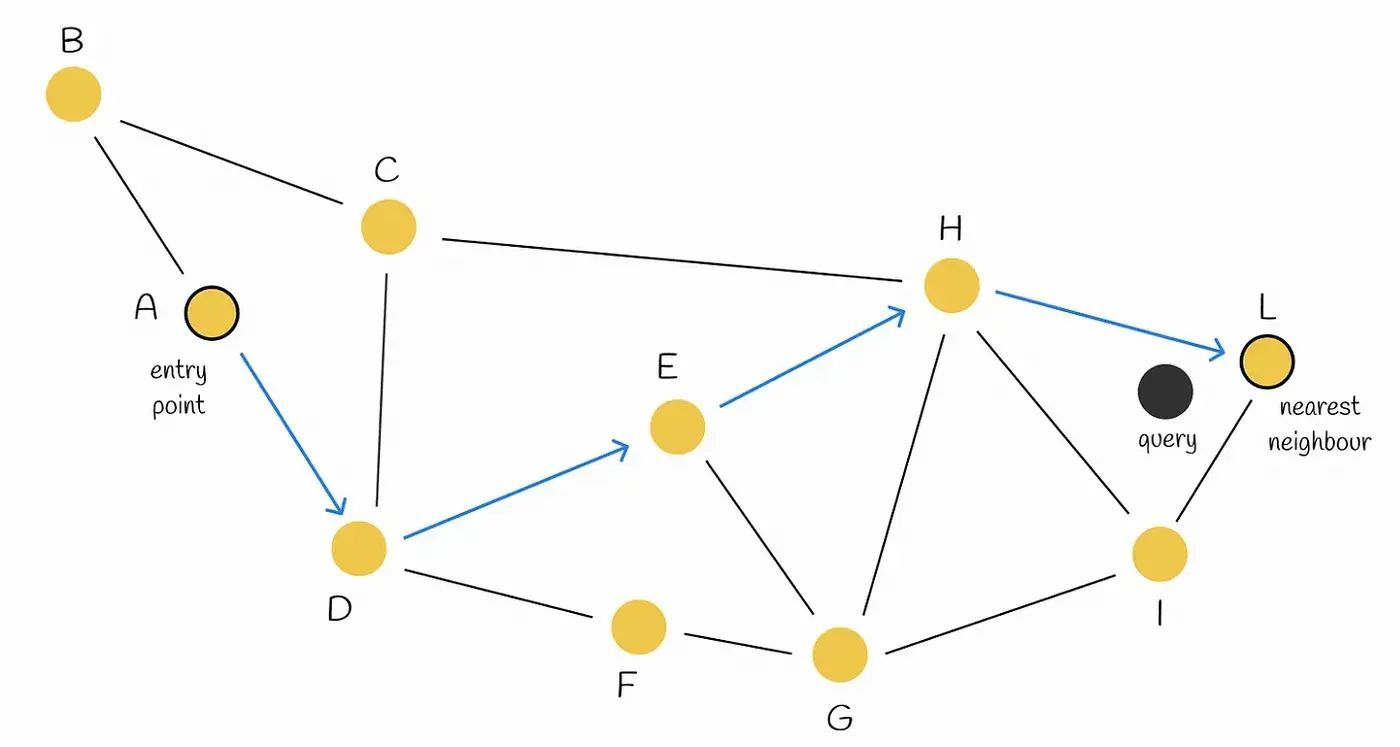
When searching an NSW graph, we begin at a pre-defined entry-point. This entry point connects to several nearby vertices. We identify which of these vertices is the closest to our query vector and move there. We repeat the greedy-routing search process of moving from vertex to vertex by identifying the nearest neighboring vertices in each friend list. Eventually, we will find no nearer vertices than our current vertex — this is a local minimum and acts as our stopping condition.
HNSW is a modified version of NSW, which borrows inspiration from hierarchical multi-layers from probability skip list structure. Below is a pictorial description of HNSW.
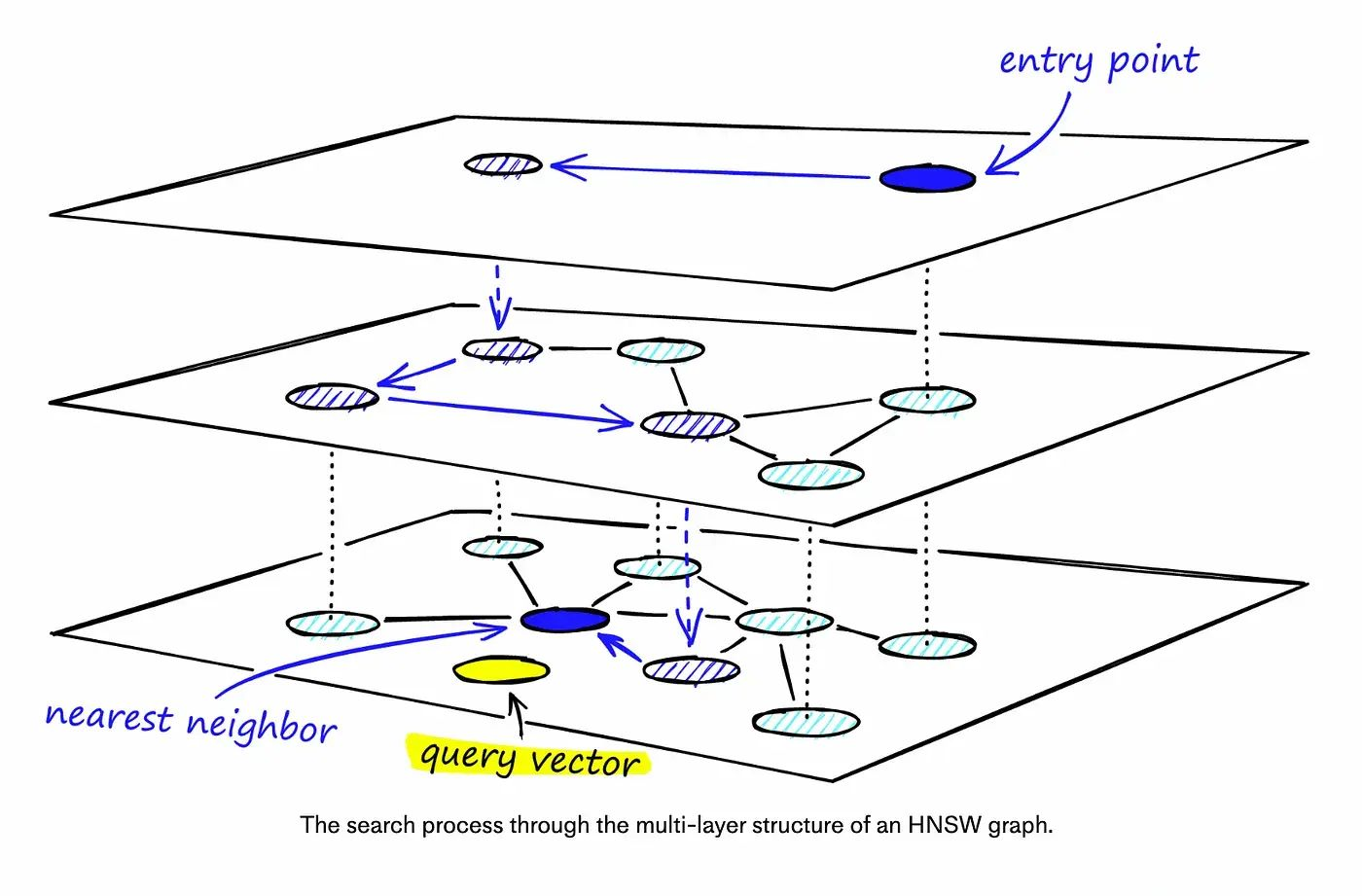
During the search, we enter the top layer, where we find the longest links. These vertices will tend to be higher-degree vertices (with links separated across multiple layers), meaning that we, by default, start in the zoom-in phase described for NSW.
We traverse edges in each layer just as we did for NSW, greedily moving to the nearest vertex until we find a local minimum. Unlike NSW, at this point, we shift to the current vertex in a lower layer and begin searching again. We repeat this process until finding the local minimum of our bottom layer — layer 0.
In our case, we are reading a PDF file containing information about stock market. Firstly, we are splitting our data and creating embeddings of it through Open AI embeddings. Finally, we are creating points corresponding to each chunk produced and dumping the list of points to Qdrant. The wait parameter is kept as True to wait for changes to actually happen.
# Read a PDF file and store the chunks in vector database
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
pdf = "Stock_Market.pdf"
text = ""
with open(pdf,'rb') as file:
pdf_reader = PdfReader(file)
for page in pdf_reader.pages:
text += page.extract_text()
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
The following is an illustration of the Qdrant architecture:
# Converting chunks into points which are central entity of Qdrant
# and putting them up on vector store
import uuid
from qdrant_client.http.models import PointStruct
points = []
for idx,chunk in enumerate(chunks):
response = openai.Embedding.create(
input=chunk,
model="text-embedding-ada-002" #OpenAI recommended
)
embeddings = response['data'][0]['embedding']
point_id = str(uuid.uuid4()) # Generate a unique ID for the point
points.append(PointStruct(id=point_id,payload={"text": chunk},vector=embeddings))
client.upsert(
collection_name="my-collection",
wait=True,
points=points
)
When a user submits a query, it is converted into a vector representation using the same embedding technique used for the data. The system then searches the index for vectors that are close to the query vector, indicating items that are semantically similar to the query.
query = "What factors determine interest rates"
response = openai.Embedding.create(
input=query,
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
search_result = client.search(
collection_name="my-collection",
query_vector=embeddings,
limit=3
)
prompt=""
for result in search_result:
prompt += result.payload['text']
concatenated_string = " ".join([prompt,query])
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": concatenated_string}
]
)
completion.choices[0].message.content
# The factors that determine interest rates include:\n-
# The demand for money: When there is high demand for borrowing,
# interest rates tend to increase. Conversely, when there is low
# demand, interest rates tend to decrease.\n- The level of government
# borrowings: Government borrowing can affect interest rates as it
# increases the demand for funds and can compete with private borrowers.
# \n- The supply of money: When the money supply increases, it can lead to
# lower interest rates as there is more money available for lending.
# Conversely, a decrease in the money supply can lead to higher interest rates.
# \n- Inflation rate: Inflation erodes the purchasing power of money, so
# lenders demand higher interest rates to compensate for the expected loss
# in value over time.\n- Policies of the central bank (such as the Reserve Bank of India)
# and government: These policies can influence interest rates through measures
# such as setting benchmark interest rates, implementing monetary policy,
# and regulating the financial sector.
The search results are ranked based on their similarity scores with the query vector. The most similar items are presented first in the search results. For our use case, the search results are sorted on basis of cosine similarity.
Vector databases can also be updated with new data over time, and the embeddings can be retrained to incorporate new information, allowing the system to adapt and improve its semantic search capabilities.
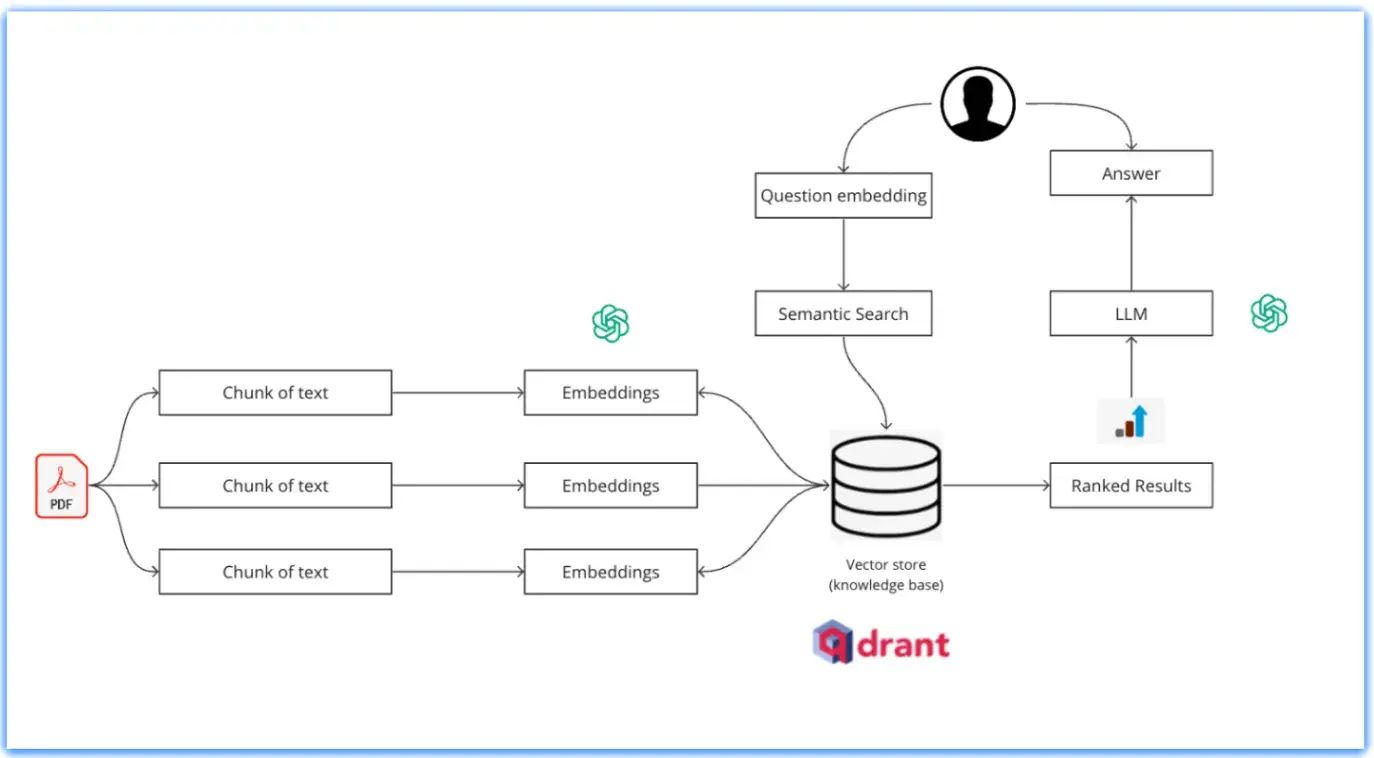
GitHub Link: GitHub - adriraj2000/Langchain_Qdrant: Understanding vector search through Qdrant


Sign up with your email address to receive news and updates from InMobi Technology