

Apache Kafka, a distributed streaming platform, offers a robust solution for handling high-volume, real-time data streams. When using Kafka on a high scale, we usually face issues with data storage and bandwidth. To overcome all these issues, we leverage compression in Kafka.
Let’s delve into the world of compression in Kafka, and explore its benefits, types of compression algorithms, and benchmarks.
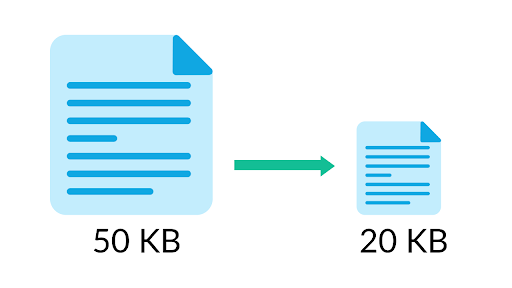
By enabling compression, we can reduce network utilization and storage, which is often a bottleneck when sending messages to Kafka. The compressed batch has the following advantage:
Much smaller producer request size (compression ratio up to 4x!)
Faster to transfer data over the network => less latency
Better throughput
Better disk utilization in Kafka (stored messages on disk are smaller)
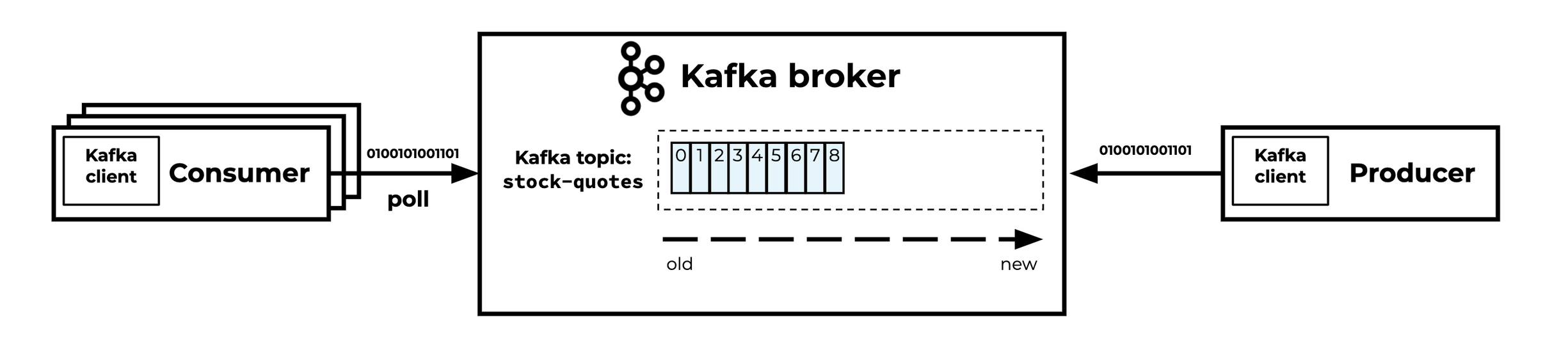
Kafka supports two types of compression: producer-side and broker-side.
Producer Side: Compression-enabled producer-side doesn’t require any configuration change in the brokers or in the consumers. Producers may choose to compress messages with a compression-type setting.
Compression options are none, Gzip, Lz4, Snappy, and Zstd.
Compression is performed by the producer client if it is enabled.
This is particularly efficient if the producer batches messages together (high throughput)
Broker Side: Compression-enabled broker-side (topic-level)
by default, topic compression is defined as compression.type=producer, we can change this config as per our requirement.
Producer-side compression is the most popular and simple to implement and here we will focus on that.
Reference: https://www.conduktor.io/kafka/kafka-message-compression
There are 4 types of compression supported by Kafka, Gzip, Lz4, Snappy, Zstd, etc.
Gzip compression is a CPU-dependent process that has different compression levels. Higher compression levels result in smaller files but are more CPU-intensive. It is based on the DEFLATE algorithm, which is a combination of LZ77 and Huffman coding.
Snappy is a fast data compression and decompression library written in C++ on ideas from LZ77. It does not aim for maximum compression or compatibility with any other compression library; instead, it aims for very high speeds and reasonable compression.
Zstandard, commonly known by the name of its reference implementation Zstd, is lossless data compression. It was designed to give a compression ratio comparable to that of the DEFLATE algorithm, but faster, especially for decompression. It is tunable with compression levels ranging from negative 7 (fastest) to 22 (slowest in compression speed, but best compression ratio).

For instance, compared to the fastest mode of Zlib, Snappy is an order of magnitude faster for most inputs, but the resulting compressed files are anywhere from 20% to 100% bigger.
Reference: GitHub - google/snappy: A fast compressor/decompressor
| Gzip | Lz4 | Snappy | Zstd | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
Medium compression ratio | |||||||
|
|
|
Moderate CPU usage | |||||||
|
|
|
|
Here are some benchmarks metrics for Gzip vs Snappy vs Zstd.
Reference: GitHub - facebook/zstd: Zstandard - Fast real-time compression algorithm
Compressor name Ratio Compression Decompress.
|
Compressor Name |
Ratio | Compression | Decompression | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
|
530 MB/s | 1700 MB/s | ||||||
|
|
|
400 MB/s | ||||||
|
|
|
2150 MB/s | ||||||
|
2.239 | 670 MB/s | 2250 MB/s | ||||||
|
|
710 MB/s | 2300 MB/s | ||||||
|
2.073 |
|
1750MB/s |
Producers group messages in a batch before sending. This is done to save network trips. If the producer is sending compressed messages, all the messages in a single producer batch are compressed together and sent as the "value" of a "wrapper message". Compression is more effective the bigger the batch of messages being sent to Kafka.
Messages Batched → Compressed Batch → Send to Kafka
Compression, however, has a small overhead on CPU resources as it involves compression and decompression.
Producers must commit some CPU cycles to compression.
Consumers must commit some CPU cycles to decompression.
Compression is a powerful feature in Apache Kafka that can optimize data transmission, improve network utilization, and enhance overall system performance. By carefully choosing the appropriate compression algorithm and configuration, you can strike a balance between compression efficiency, CPU usage, and latency requirements.


Sign up with your email address to receive news and updates from InMobi Technology